Power BI projenizde aynı anda birden fazla kapsamı başlattıysanız, her bir kapsam için ayrı bir developer ya da ekip varsa bazı best-practice kurallarına uymak hayatımızı kolaylaştırabilir!
Genelde durum şöyle oluyor: Bir ekip diyelim satış-bütçe kapsamı çalışırken diğer ekip stok-lojistik çalışıyor. Her iki kapsamda da büyük ihtimalle Müşteri ve Ürün boyut tabloları ortak ya da benzerlikleri çok! Eğer kapsamları ayrı ayrı modelleyip bir noktadan sonra birleştirmeyi düşünüyorsanız yapmanız gereken ilk şey şemalarla çalışmak!
Verinin büyük oranda SQL/Oracle gibi nizami bir veritabanından geldiğini varsayıyorum. Geliştirme yaparken canlı sistemdeki tablolara doğrudan bağlantı yapmak yapabileceğiniz en kötü şey! Bir Test ya da Dev ortamı yaratın, bu başka bir sunucudaki bir SQL DB olabilir. Canlı sistemden makul büyüklükteki transaction datası ile boyut tablolarını bu ortama bir şema altında aktarın. Bu da mümkünse default dbo şeması olmasın!
Canlı sistemden Dev/Test ortamına veri aktarmanın birden fazla yöntemi var, hangisini uygun görüyorsanız onu kullanın. Lazım olan tabloları tüm sütunlarıyla çekmek yerine kapsamlarda size lazım olacak sütunları seçin sadece. Eğer T-SQL ile yapacaksanız bunun için basit bir SELECT şu şu sütunları demek, eğer transaction tablosu ise tarih sütununa bir WHERE condition eklemek yeterli. Kendi lokalimde bir test/dev ortamı oluşturmak için kullandığım yöntem genellikle boş bir Power BI dosyasıyla veriyi canlı ortamdan -bir seferliğine- çekip DAX Studio ile kendi lokalimdeki SQL sunucuya aktarmak. DAX Studio’nun Advanced menüsü altındaki SQL Server opsiyonunu bunun için kullanabilirsiniz. Son derece hızlı ve zahmetsiz!
Her ekip aynı şemayla mı farklı şemayla mı çalışsın? Duruma göre değişebilir, eğer ortak boyut tablolarının yapısını kolay yönetebileceğinizi düşünüyorsanız tek şema daha uygun olabilir. Ama benim gördüğüm genellikle kolay gibi gözükse de sorunlar çıktığı yönünde! Bir kapsama lazım olan X sütununu 3 join’le diğer tablolardan getirirken öteki ekibin çalışmasını aksatabilirsiniz. Garantiye alayım diyorsanız her ekip için ayrı şema yaratın, size kalmış biraz.
Buraya kadar olan kısmı kısaca özetlemek gerekirse; asla canlı sistem üzerinde geliştirme yapmayın, dev/test ortamında çalışın ve şemaları kullanın!
Dev/Test ortamını hazırladık, güzel, direkt bağlanıp modeli geliştirmeye mi başlayalım? Hayır! Dev ortamında kurduğumuz modeli bir süre sonra belki diğer kapsamla birleştireceğiz! Tüm modeli tamamladıktan sonra tüm sorguların veri kaynaklarını canlıya (ya da canlının lazım olan datasını içeren bir replikasına) çevireceğiz! Bunu tek tek her bir sorgu için elle yapmak hem hataya açık hem de daha uzun sürer. Üstelik Dev ortamında çalışırken bile tüm dataları -özellikle transaction datasını- komple çekmek istemeyiz. 100 milyon satırlı stok tablosunun tamamı üzerinden geliştirme yapmak çok anlamlı değil. Çalıştığımız veri büyüklüğünü sınırlamak isteyebiliriz.
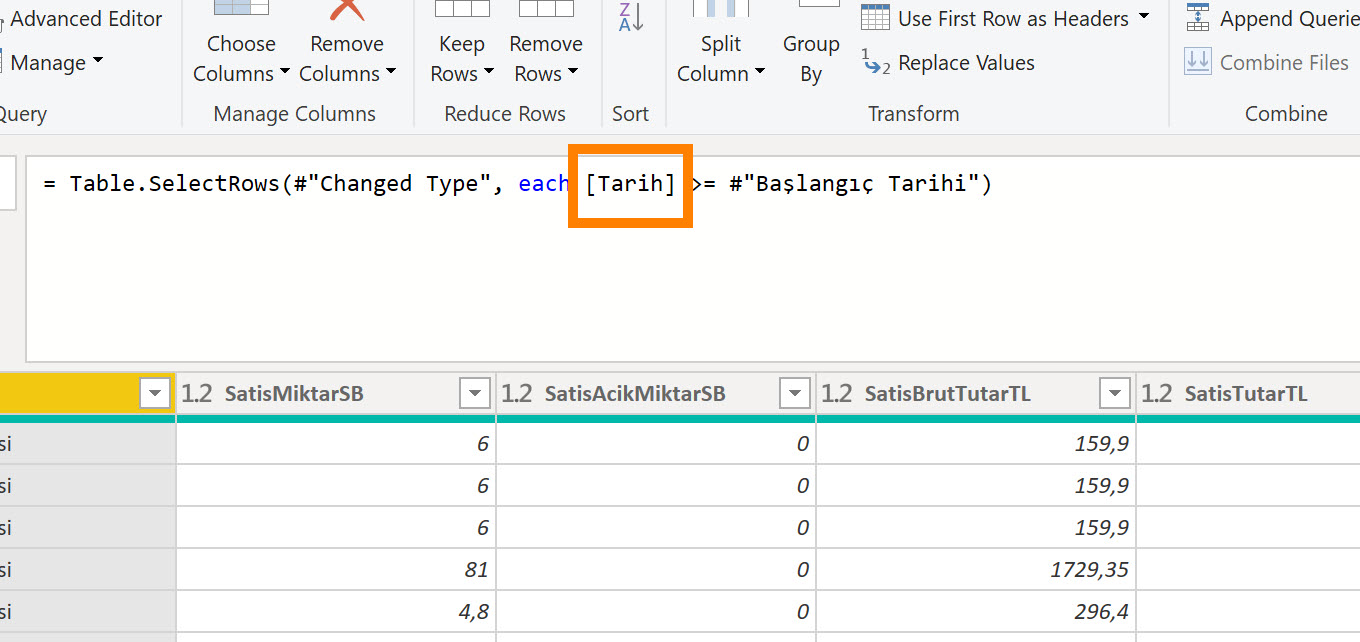
Bunları yapabilmek için Power Query tarafındaki parametreleri kullanmak en doğru yöntem! Sunucu adı, veritabanı adı, şema adı, transaction tablosundaki satır sayısı ya da tarih filtresi gibi parametreler oluşturup tüm bağlantıları bu parametreler üzerinden yapabiliriz.
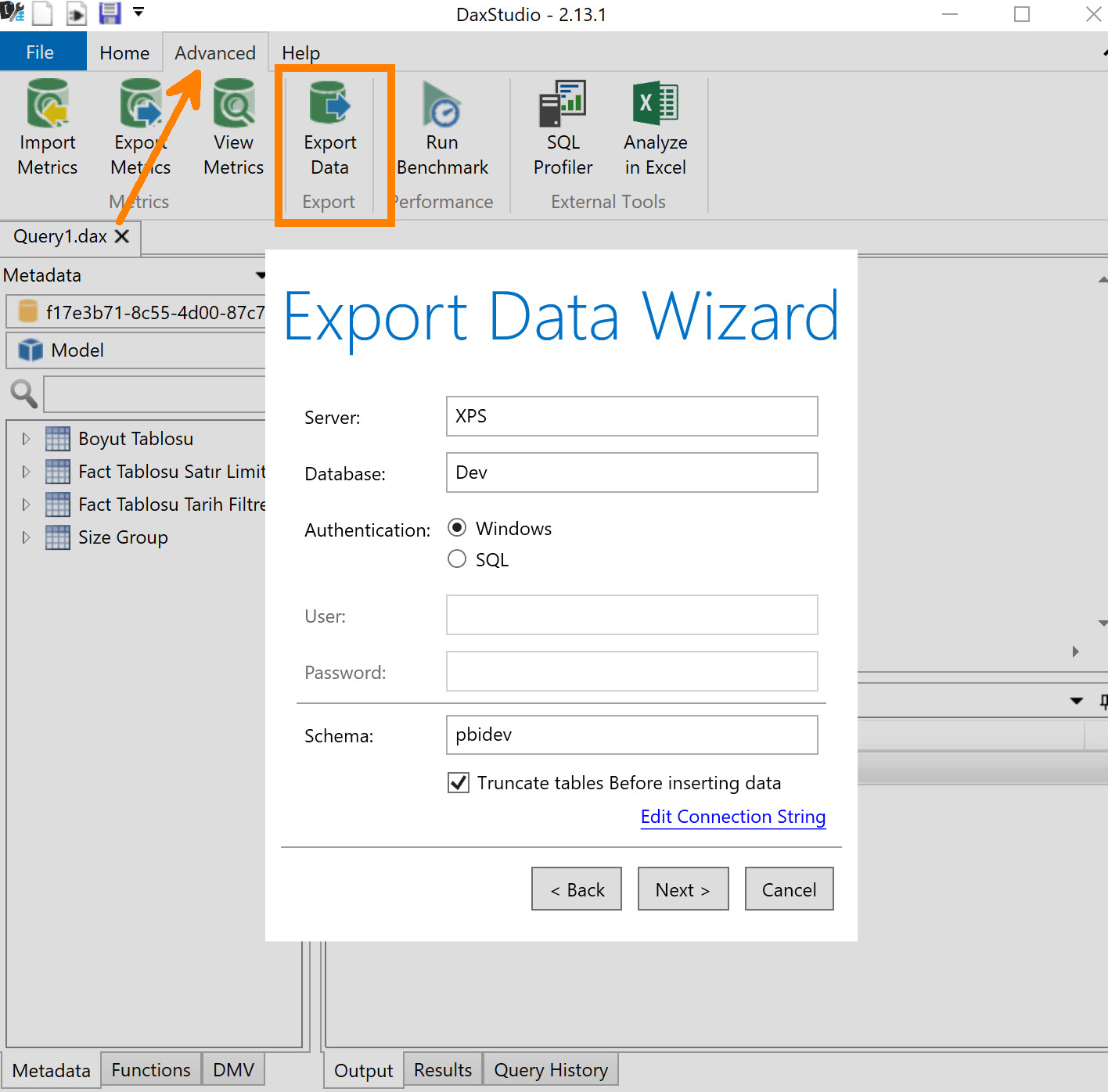
Ben bu amaçla resimdeki parametreleri içeren bir template kullanıyorum.
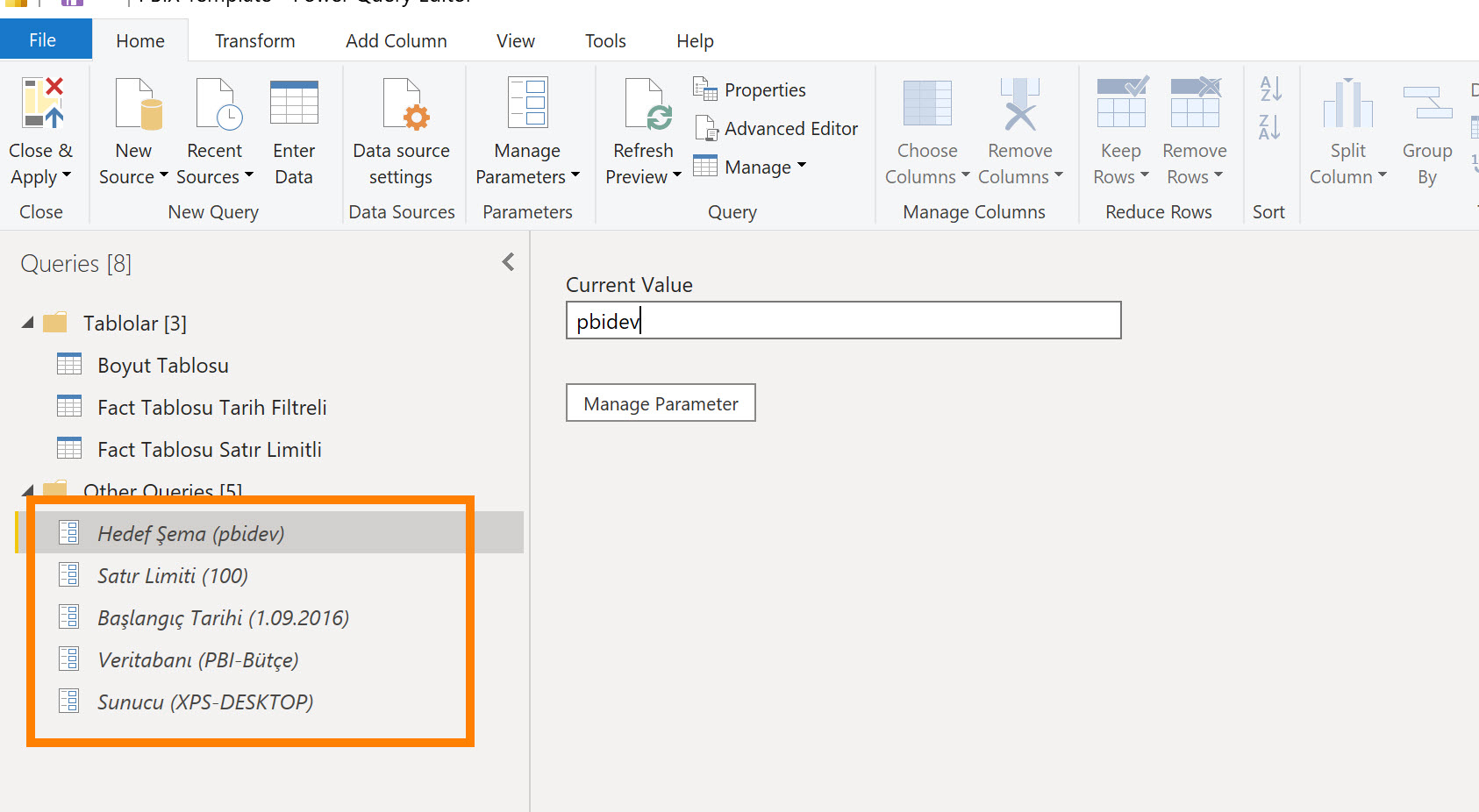
Mantık basit, misal sunucuya bağlandığım stepte gerçek sunucunun adını yazmak yerine ilgili parametreyi veriyorum, parametrenin default değeri neyse o sunucuya bağlanacak! Transaction tablosunu çekerken bazen tarih filtresi kullanıyorum bazen ilk 10000 satır gelsin diyorum. Her ikisi için de birer parametre tanımlı!
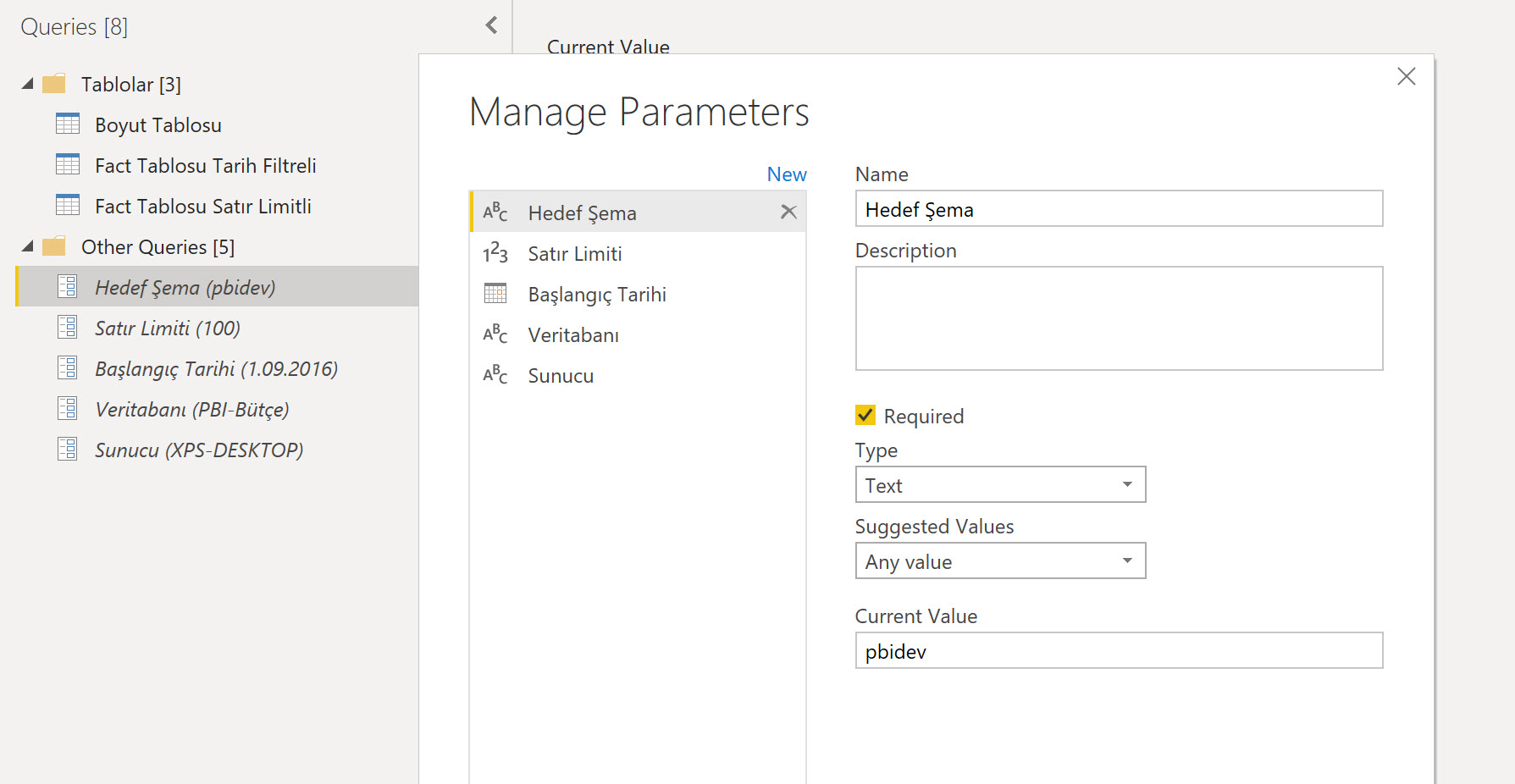
Eğer böyle parametrik bir dosyayla çalışırsanız 30 saniye içerisinse modelinizi test sistemden canlı/DW sisteme taşıyabilirsiniz. Tablo/view/sütun isimleri her iki ortamda da aynı olduğu sürece hiçbir sorun çıkmaz!
Eğer bu dosyayı birebir kullanmak isterseniz kodu açtığınızda görürsünüz ama gene de eklemiş olayım: Satır Limiti parametesi, transaction veya boyut tablosundaki top X satırı çekecek veya tüm tabloyu çekecek. Eğer negatif bir değer verirseniz tüm tabloyu çekecek, yoksa kaç yazdıysanız o kadar satırı çekecek.
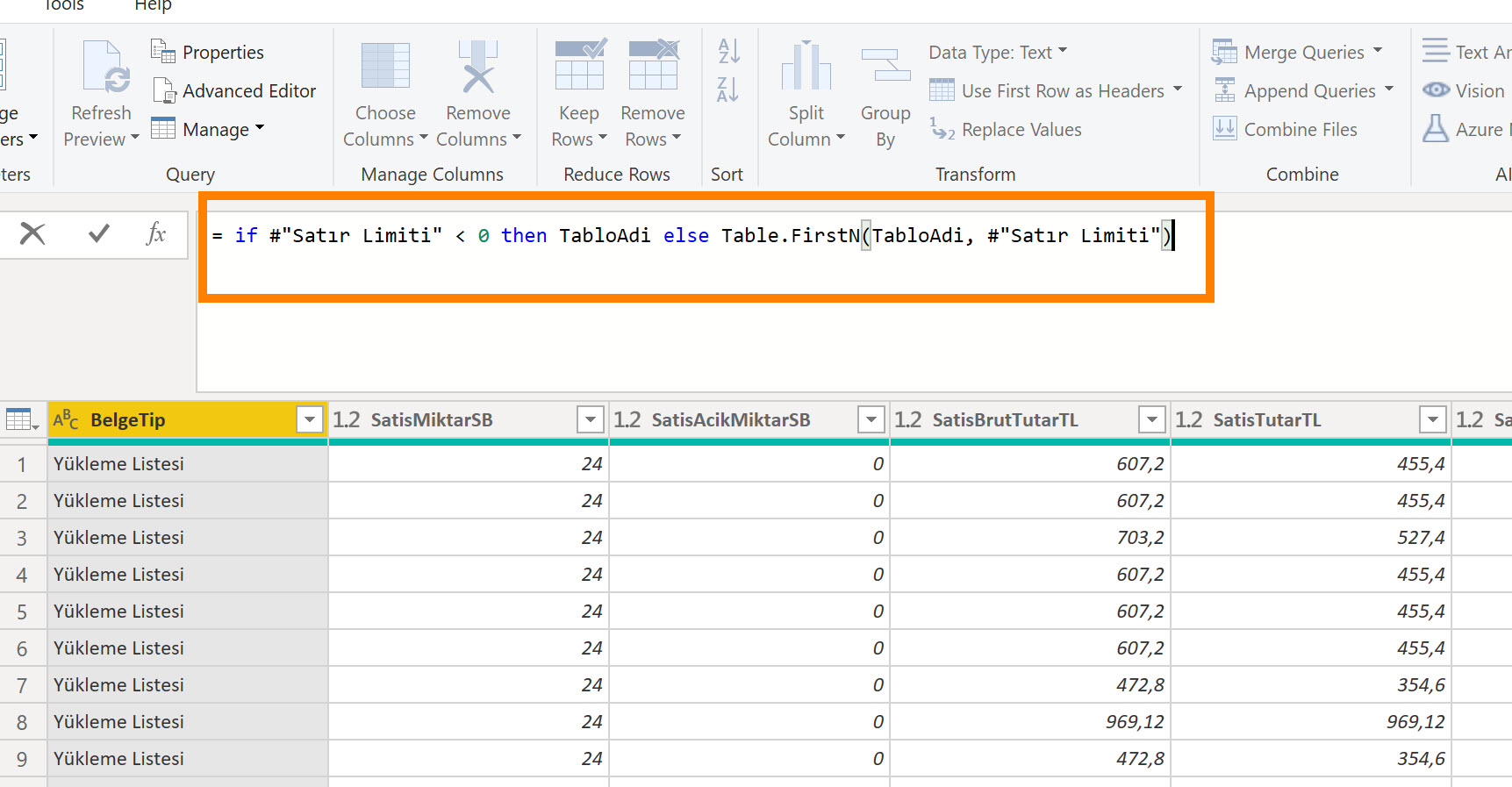
Başlangıç Tarihi X tarihten sonraki transaction datasını çekecek, ilgili tablodaki tarih sütununuz hangisiyse kodu ona göre revize etmeniz lazım!
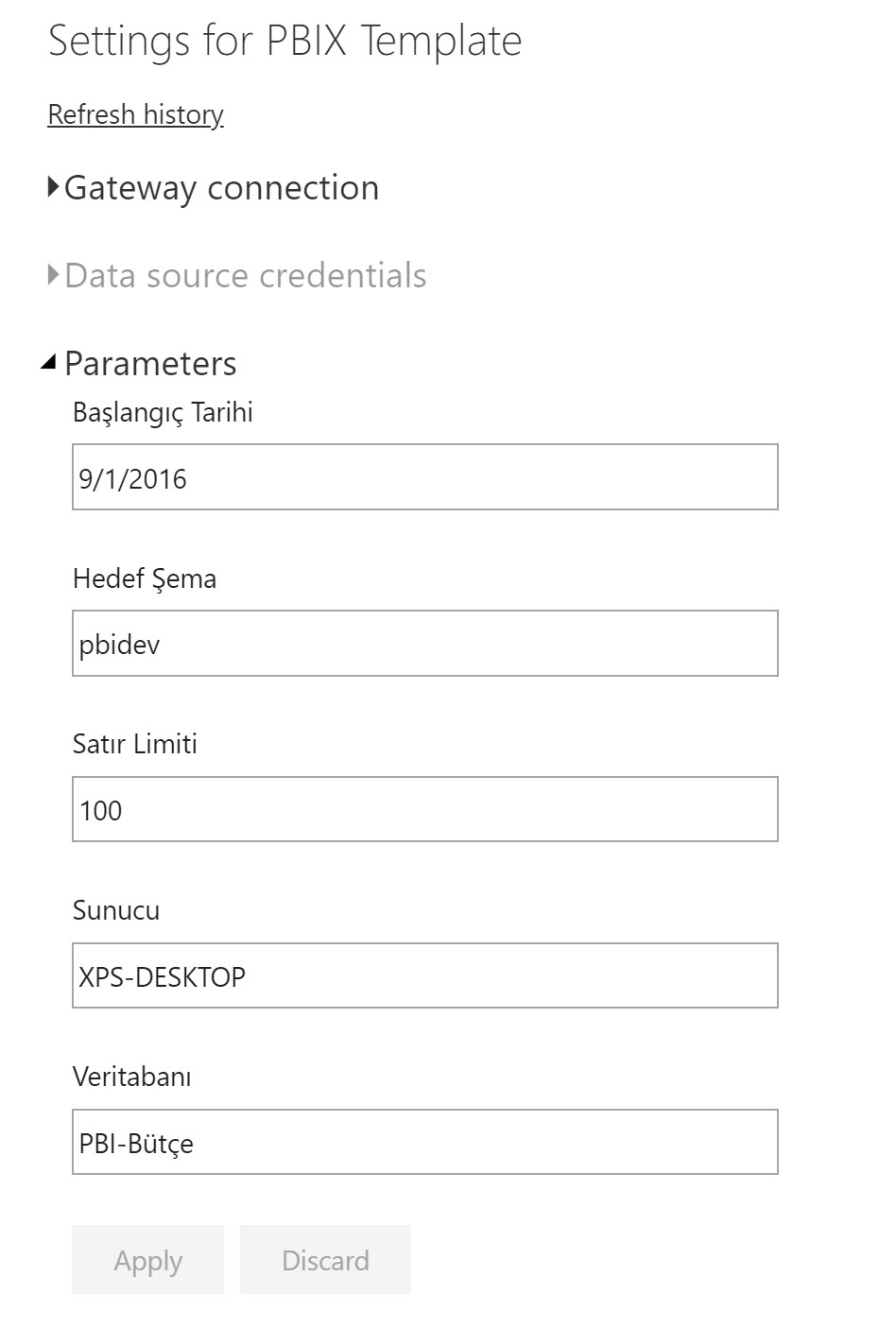
Parametre kullanmanın bir güzel tarafı da şu: Tanımlandığımız parametrelerin hepsi, modeli publish ettiğimizde ilgili dataset’in refresh ayarlarında çıkacak. Bulut servisindeyken bile modeli dev/test’ten canlıya yönlendirmek mümkün!
…
Proje geliştiren arkadaşlara bir diğer önerim de çalışma alanlarının kullanımı, eğer Premium lisansınız varsa “Deployment Pipeline” ‘ları kullanmak ve raporları datasete bağlanarak geliştirmek olacak, bunun için ayrı bir yazı yazacağım.
** Daha önceki öneri yazılarına gözatmak isterseniz buradan ve buradan.
Yazıdaki template’i -bloga üyeyseniz- indirebilirsiniz.
Sadece üyeler görebilir. Hızlı üyelik için sosyal medya hesabınızla giriş yapabilirsiniz!