Power BI ‘da DAX ile bir metrik (ölçü) formülü yazdığımızda, her ne formülü olursa olsun, çalışmaya başlamadan önce, hesaplama yapacağı hücrenin (noktanın) context’ini bulur. Context -en basit tanımıyla- ilgili hücreyi hesaplarken tabular engine’nin gördüğü filtrelenmiş veri kümesidir. Bu filtrelenmiş veri kümesini iki farklı context kavramı tetikler; filter context, + eğer formülümüzde bir iterator varsa row context.
Filter Context
Satışlar :=
SUMX ( 'Satışlar' ; 'Satışlar'[Miktar] * 'Satışlar'[Fiyat] )
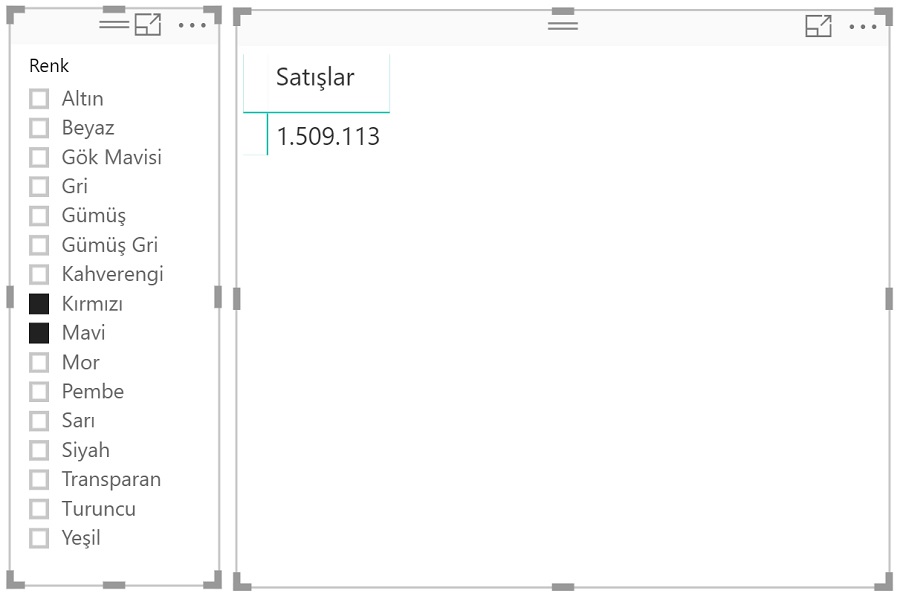
Dilimleyicide kırmızı ve mavi renkler seçili: Tabular engine şu an formülü hesaplarken sadece ve sadece bu renk ürünlerin satışlarını görüyor. Matristeki hücre için context şu an bu: Satışlar tablosunda, rengi kırmızı ve mavi olan ürünlerin olduğu satırlar. Yani orijinal tablonun filtrelenmiş halini görüyor.
Matrise renk ve yıl sütunlarını düşürelim.
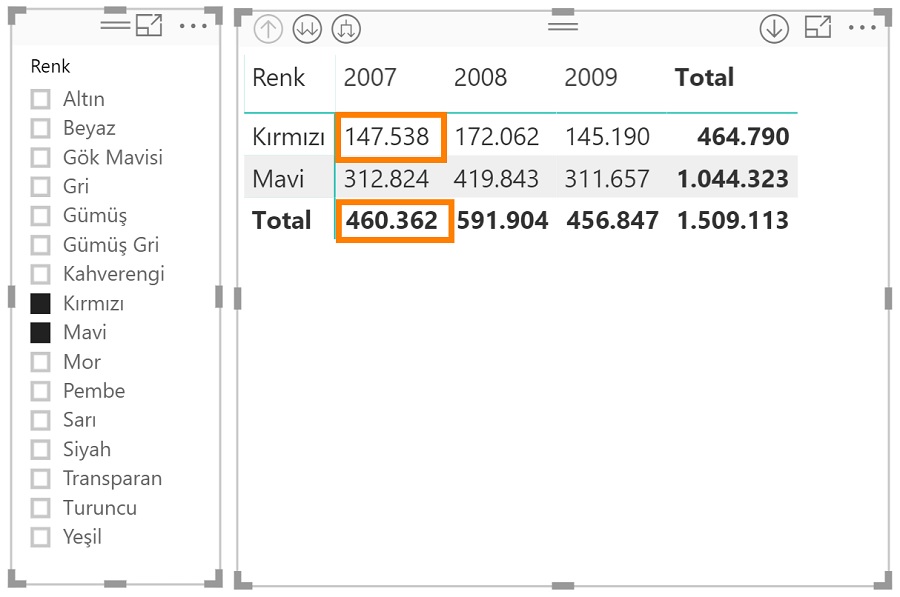
Matrisi oluştururken diğer renkleri göremediği için sadece kırmızı ve mavi için satırlar oluşturdu.
2007-Kırmızı hücresini hesaplarken gördüğü context: Satışlar tablosunda, 2007 yılına ait tarihlerin ve sadece kırmızı ürünlerin olduğu tablo. Orijinal tablonun, Yıl= 2007 ve Renk= Kırmızı olarak filtrelenmiş hali.
Total satırı için gördüğü context: Bu hücre matristeki Renk sütunundan etkilenmiyor, ama matrisin dışındaki dilimleyicide yapılan seçimlerden etkileniyor. Satışlar tablosunda 2007 yılına ait kırmızı ve mavi ürünlerin olduğu tabloyu görüyor.
Kırmızı ve mavi için bulduğum değerleri toplayayım demiyor, total hücresi için context’i buluyor ve formülü bu context’e göre hesaplıyor.
Dilimleyicide yapılan her seçim, matriste satıra veya sütuna koyduğumuz renk ve yıl, tabular engine’nin gördüğü veri kümesini hep filtreliyor. Bu yüzden de bu konseptin adı: Filter Context.
Filter context, modeldeki tablolar arasında bulunan ilişkiler boyunca ok yönünde akar. Buna da filter propagation adı veriliyor.
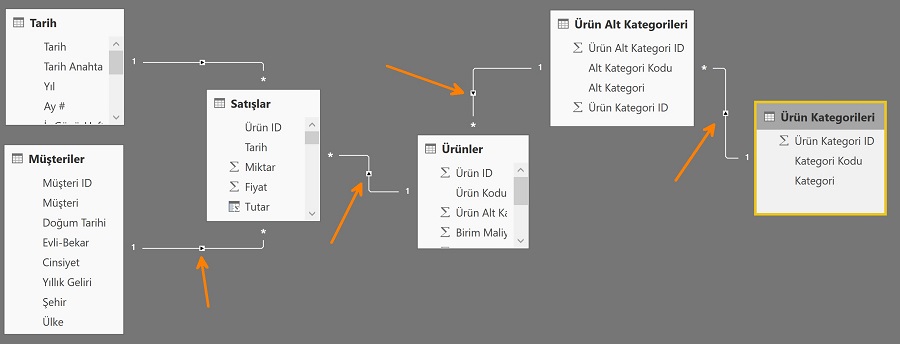
Matrise “Ürün Kategorileri” tablosundan “Kategori” sütununu düşürdüğümüzde, her bir kategori değeri için ilgili alt kategorileri bulur, bu alt kategorilere ait ürünleri bulur, bu ürünlere ait satış satırlarının olduğu tabloyu görür.
Benzer şekilde, “Tarih” tablosundan “Yıl” sütununu düşürdüğümüzde her bir değer için satışlar tablosunu filtreler.
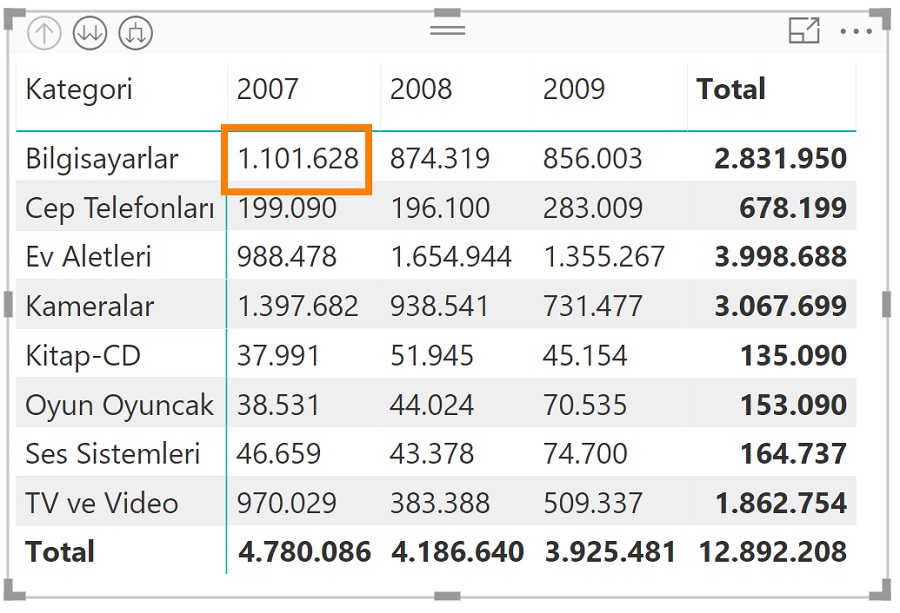
Matristeki işaretli hücre için, kategorisi bilgisayar olan alt kategorileri bulur, bu alt kategorilere ait ürünleri bulur, bu ürünlerin satış satırlarını bulur ve bu setten de tarih sütunu 2007 yılına ait olan satırları filtreler. Ve bu işlemi matristeki her hücre için tekrarlar.
Bazı cümleleri fazla tekrarlamama müsade edin, çünkü DAX Man’in kurduğu cümleler aynen böyle!
Filter propagation ile ilgili, yani filtrelerin akışıyla ilgili bu yazıya da göz atmanızı önereceğim, çünkü bazen filtrelerin çift yönlü akmasına ihtiyaç duyabiliriz.
Row Context
DAX’ta row context yaratan iki şey var: iterator fonksiyonlar (sonu X ile bitenler + FILTER gibi komutlar) ve hesaplanmış sütunlar.
Row context en basit tanımıyla bulunduğumuz satır demek, hangi satırda olduğumuzun farkında olmak demek.
Örneğin satışlar tablosuna miktar ve fiyat bilgilerini çarparak hesaplanmış bir tutar sütunu ekleyelim:
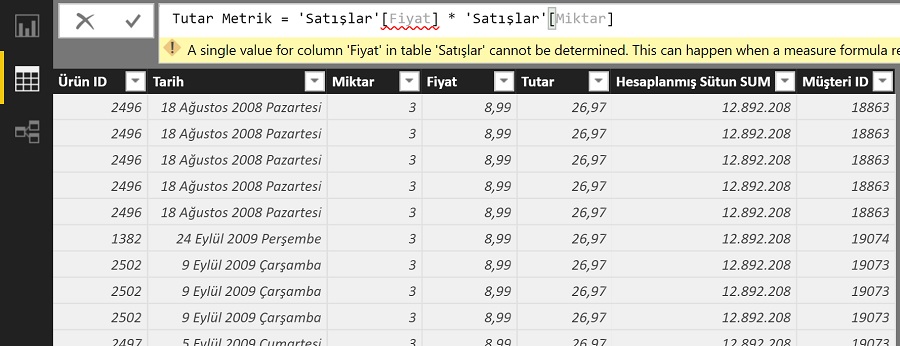
Tutar = 'Satışlar'[Fiyat] * 'Satışlar'[Miktar]
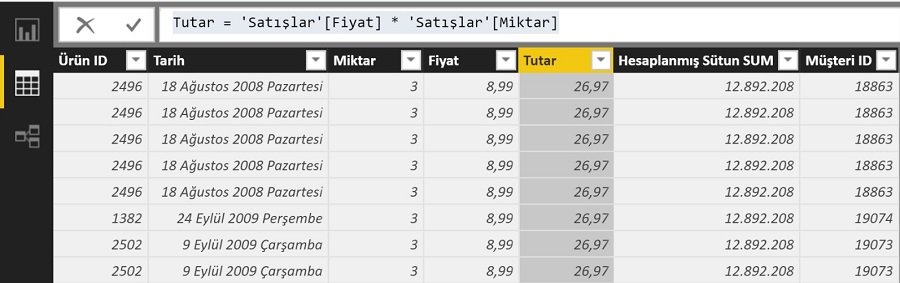
Formülde herhangi bir fonksiyon yok, basit bit aritmetik işlem içeriyor sadece. Hesaplanmış sütun row context yarattığı için formül çalışıyor ve çalışırken bulunduğu satırın farkında, her bir satır için işlem yapıyor.
Aynı formülü metrik olarak eklemeye kalksak hata mesajı vererek çalışmayacaktır.
Row context yaratan diğer bir konseptten, iterator’lardan devam edelim. Iteratorlar, çalışması için bir tablo verdiğinizde, belirttiğiniz işlemi her bir satır için tek tek yapan, bulunduğu satırdaki sütun değerlerinin farkında olan bir fonksiyon grubu.
Satışları hesaplayan formülümüz SUMX ile başlıyor, yani bir iterator.
Satışlar :=
SUMX (
'Satışlar' ; -- Mevcut Filter Context
'Satışlar'[Miktar]*'Satışlar'[Fiyat] -- Mevcut Filter Context + Row Context
)
Formül hesaplama yapmaya başlamadan önce, verdiğimiz Satışlar tablosunda gördüğü şey, mevcut filter context’ten gelen satırları içeren Satışlar tablosudur. Bu filter context’teki satırları içeren tabloda bulduğu satırlar üzerinde işlem yapar.
Bir başka deyişle, iterator fonksiyonlar, verdiğimiz tablodaki filter context üzerine yeni bir row context ekler.
** Bunun tek istisnası, önceki context’in bir filter context değil de, aynı tablo üzerindeki bir başka row context olması durumunda gerçekleşir. Bu durumda yeni yaratılan row context, önceki row context’i görmezden gelir. Kafa karıştırıcı bir cümle gibi, gerçekten de öyle, o yüzden bu paragrafı sadece not olarak görün, EARLIER fonksiyonu ile ilgili bir yazı yazdığımda durum netleşecek.
Filter context, tablolar arasındaki ilişkileri otomatik olarak görüyordu. Fakat row context, sadece bulunduğu satırdaki sütun değerlerinin farkındadır. Tablolar arasındaki ilişkilerin farkında değildir.
Örneğin satışlar tablosuna, ilgili ürünün satış fiyatıyla birim maliyeti arasındaki farkı hesaplayacak bir hesaplanmış sütun eklemeye çalışalım.
Kar HS = 'Satışlar'[Fiyat]-'Ürünler'[Birim Maliyet]
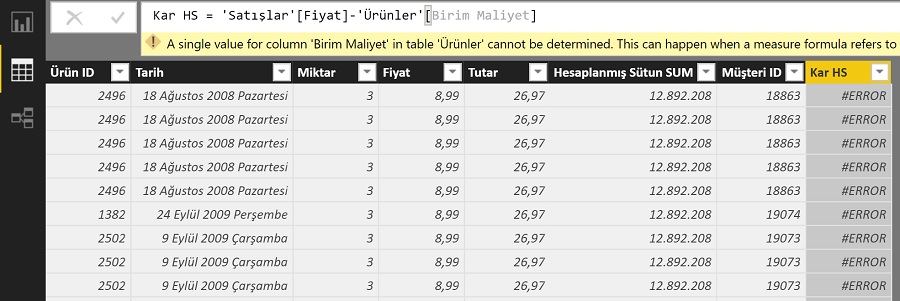
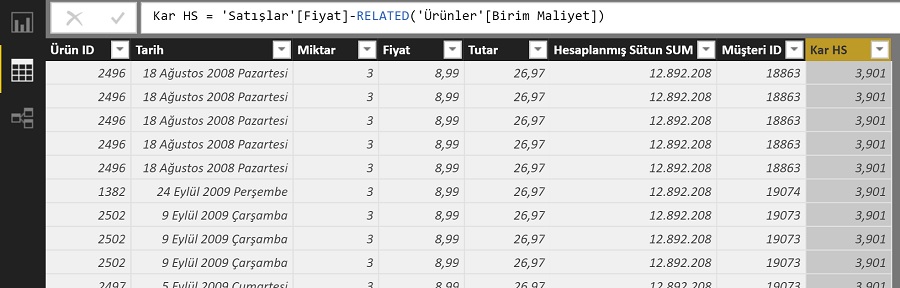
Bulunduğu satırdaki ürünün Ürünler tablosundaki değerlerini göremediği için hata veriyor. Farkında olmasını sağlamak için RELATED ile birlikte kullanmalıyız.
Kar HS = 'Satışlar'[Fiyat] - RELATED( 'Ürünler'[Birim Maliyet] )
Benzer şekilde “many” tarafındaki tabloların farkında olmasını istiyorsak RELATEDTABLE kullanmalıyız. Ürünün kaç kez satıldığını hesaplayacak bir hesaplanmış sütunu “Ürünler” tablosuna ekleyelim.
Kaç Kez Satıldı = COUNTROWS(RELATEDTABLE( 'Satışlar' ) )
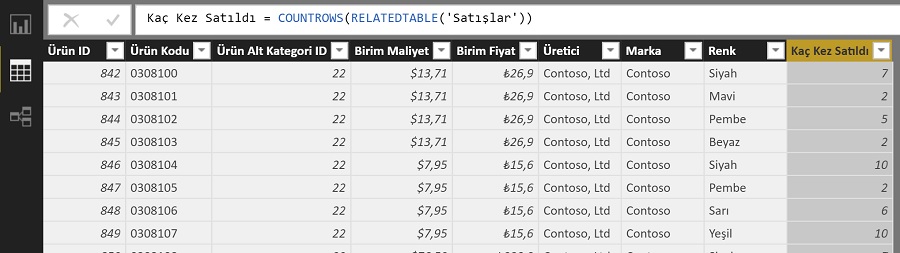
** RELATED ve RELATEDTABLE ile ilgili yazıya göz atmak isterseniz buradan.
Yazdığımız formülde birden fazla iterator varsa, bu durumda her bir iterator kendi row context’ini yaratır, yani içiçe (nested) row context’ler olabilir. Örneğin her bir kategorinin ortalama satışlarını hesaplayalım:
Ortalama Kategori Satışları :=
AVERAGEX (
'Ürün Kategorileri';
SUMX( RELATEDTABLE('Satışlar' );
'Satışlar'[Fiyat] * 'Satışlar'[Miktar]
)
)
Her bir ürün kategorisi için, ilgili kategorinin satışlarını Satışlar tablosunda bul ve topla, tüm kategorileri bitirdiğinde her bir kategori için bulduğun değerlerin ortalamasını al!
İlk row context en dıştaki AVERAGEX ile başlıyor, her bir kategori için Satışlar tablosunda (ilgili satırlarda) SUMX ile ikinci bir row context yaratıyor.
Önceki yazılarda bahsettiğimiz COUNTROWS, FILTER gibi fonksiyonlarla bir başka örnek daha yapalım, örneğin altında 300’den fazla ürün olan kategorilerin satışlarını hesaplayalım:
300 den Fazla Ürün İçeren Kategori Satışları :=
SUMX (
FILTER('Ürün Kategorileri' ;
COUNTROWS( RELATEDTABLE('Ürünler')) > 300
) ;
SUMX( RELATEDTABLE( 'Satışlar' ) ; 'Satışlar'[Tutar] )
)
Context, filter context + row context’ten oluşur. Yazdığımız tüm formüller, her bir hücre için bu context’i bulur ve ona göre çalışır. SUM(‘Satışlar'[Tutar]) gibi basit formüllerde row context oluşmaz ama biz gene de her iki context de her zaman aynı anda mevcuttur diye düşünelim (row context boş küme gibi).
Yazıdaki modeli indirebilirsiniz.
Sadece üyeler görebilir. Hızlı üyelik için sosyal medya hesabınızla giriş yapabilirsiniz!