RANKX ile ilgili örneklere devam ediyorum, filter context ve row context’i açmak adına çok güzel bir fonksiyon olduğunu yazarken daha iyi farkettim. Önceki yazılara da göz atmak isteyebilirsiniz: 1, 2
Aşağıdaki gibi bir veri setimiz var.

Tutar değeri aynı olan birden fazla müşteri var ve bazı müşterilerde tutar yok. Metriklerimiz şöyle:
İadeler := SUM ('Müşteri İadeleri'[İade Tutarı] )
Büyükten Küçüğe :=
RANKX (ALLSELECTED ('Müşteri İadeleri'); [İadeler] )
Küçükten Büyüğe :=
RANKX ( ALLSELECTED ('Müşteri İadeleri'); [İadeler]; ; ASC )
Hepsini aynı matrise düşürüyorum.
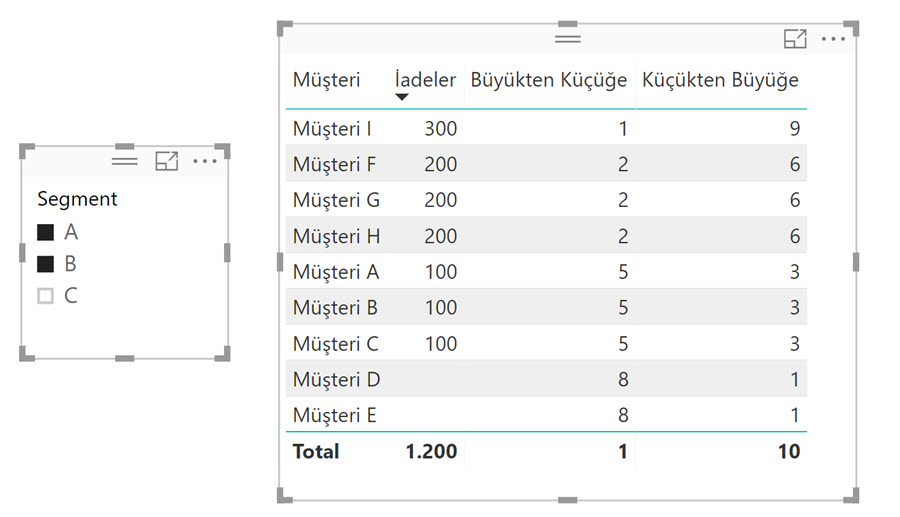
ALLSELECTED (‘Müşteri İadeleri’) sonucunda kalan müşteriler tablosu neyse, her iki sıralama metriği de, matristeki her bir müşteri satırı için bu tablonun tüm satırlarını iterate edecek.
“Büyükten Küçüğe” metriğinin neyi gördüğünü bulalım:
Büyükten Küçüğe Neyi Görüyor :=
CONCATENATEX ( ALLSELECTED ('Müşteri İadeleri'); [İadeler] ; "-" )
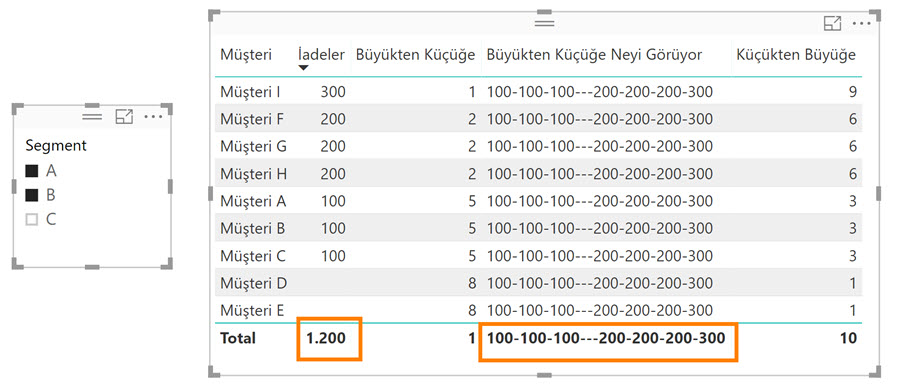
İlk sıradaki “Müşteri I” için filter context ‘te metrik çalışmaya başlamadan önce sadece kendisi var. ALLSELECTED (..) ile seçili tüm müşterileri gördü (filter context’i değişti). Bu tabloda gördüğü her bir satır için [İadeler] ‘i hesapladı, en sonunda bulunduğu satırdaki müşterinin değerine göre (300’e göre) sırasını buldu.
Aynı işlemi ikinci sıradaki Müşteri F için yaptı. Müşteri G için yaptı … Ta ki matristeki tüm müşterileri bitirene kadar.
CONCATENATEX ile matristeki her bir satır için iterate edilen tabloda gördüğü değerlerin listelenebiliyor olması, iterator’ların çalışma mantığını anlamak açısından güzel bir örnek. (Bir diğer güzel örnek de EARLIER fonksiyonu, buna da göz atmak isteyebilirsiniz.)
Metrik çalışmaya başlamadan önce gördüğü filter context’te sadece kendisi var cümlesi için de bu yazıya lütfen.
Toplam satırı için niye 1 gösteriyor: Bu satır için [İadeler] metriğinin değeri 1,200, gördüğü listedeki değerlerden daha yüksek, bu yüzden 1 gösteriyor.
[Küçükten Büyüğe] metriğinin olduğu sütundaki toplam satırında 10 göstermesinin gerekçesi de aynı, elinde 9 tane değer var (boşlar dahil), 1200 hepsinden daha büyük, sıralamayı ters yaptığımız için de bu sefer 10 hesaplıyor.
…
Matristeki değerlerden kaynaklanan sıra numaralarını düzeltmeye çalışalım:
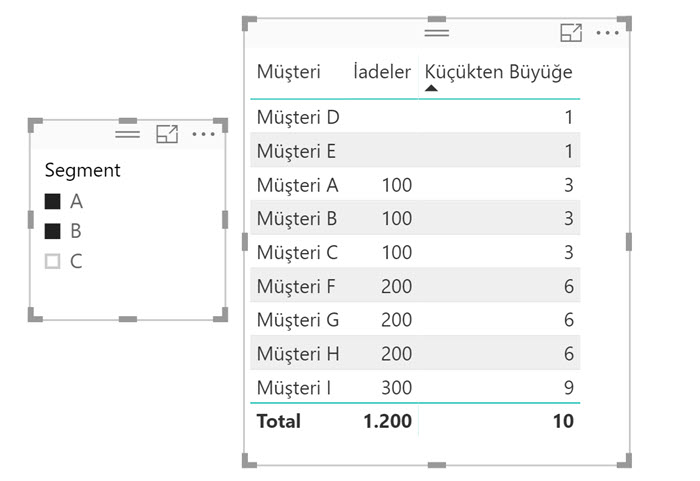
Bazı değerler “boş” olsa da RANKX bunları bir değer olarak dikkate alıyor. Almamasını sağlayabiliriz, yapmamız gereken şeylerden biri RANKX’in iterate ettiği tabloyu, [İadeler] metriği ya da ‘Müşteri İadeleri'[İade Tutarı] sütun değeri “boş olmayacak” şekilde filtrelemek.
Deneyelim:
Küçükten Büyüğe Deneme 1 :=
RANKX (
FILTER (
ALLSELECTED ( 'Müşteri İadeleri' );
'Müşteri İadeleri'[İade Tutarı] > 0
);
[İadeler];
;
ASC
)
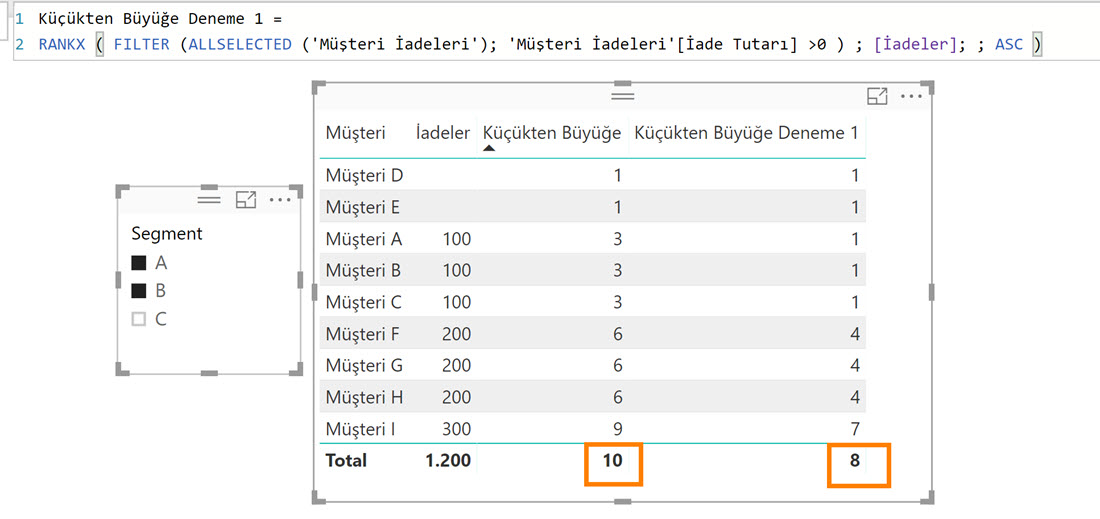
Tam istediğimiz gibi olmadı henüz!
Fakat rakamların değiştiğine dikkatinizi çekerim. FILTER koşulu ile yazdığımız kısım aslında tabloyu iade tutarı olan satırlar şeklinde filtreledi, RANKX’in iterate ettiği tabloda artık bu boş satırlar yok, her iki sıralamanın gördüğü değer listesine bakalım:
Küçükten Büyüğe Neyi Görüyor :=
CONCATENATEX ( ALLSELECTED ('Müşteri İadeleri') ; [İadeler] ; "-" )
Küçükten Büyüğe Deneme 1 Neyi Görüyor =
CONCATENATEX (
FILTER (
ALLSELECTED ( 'Müşteri İadeleri' ),
'Müşteri İadeleri'[İade Tutarı] > 0
),
[İadeler],
"-"
)
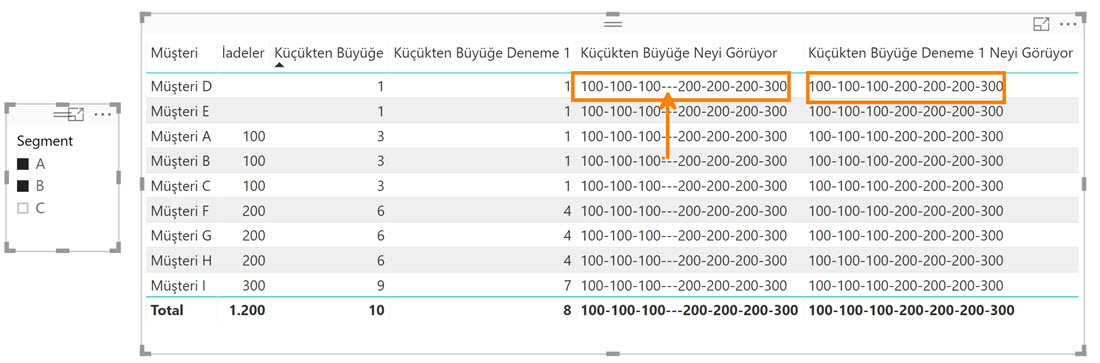
RANKX ‘in iterate ettiği tabloda boş değerli satırlar yok ama Müşteri D ve E için bu müşterilerin boş değerlerini gördüğü listeyle karşılaştırmaya devam ediyor!
Eğer [İadeler] metriği boş ise sıralama yapmamasını sağlamalıyız!
Küçükten Büyüğe Deneme 2 =
IF (
NOT ( ISBLANK ( [İadeler] ) ),
RANKX (
FILTER (
ALLSELECTED ( 'Müşteri İadeleri' ),
'Müşteri İadeleri'[İade Tutarı] > 0
),
[İadeler],
,
ASC
)
)
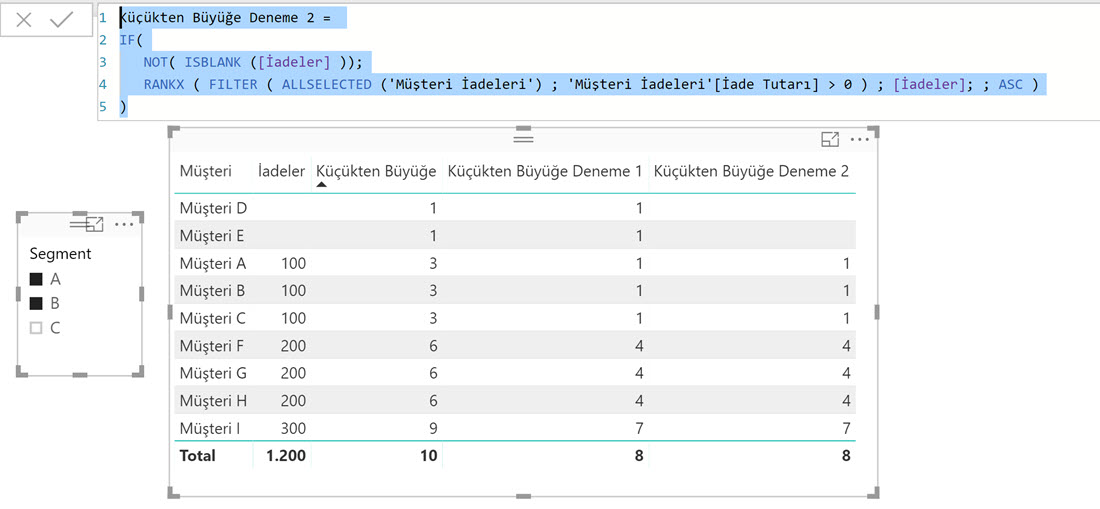
1-4-7 diye giden sıralamayı 1-2-3 şeklinde değiştirmek için RANKX’in opsiyonel parametrelerinden SKIP-DENSE ‘i kullanabiliriz.
Küçükten Büyüğe Deneme 3 =
IF (
NOT ( ISBLANK ( [İadeler] ) ),
RANKX (
FILTER (
ALLSELECTED ( 'Müşteri İadeleri' ),
'Müşteri İadeleri'[İade Tutarı] > 0
),
[İadeler],
,
ASC,
DENSE
)
)
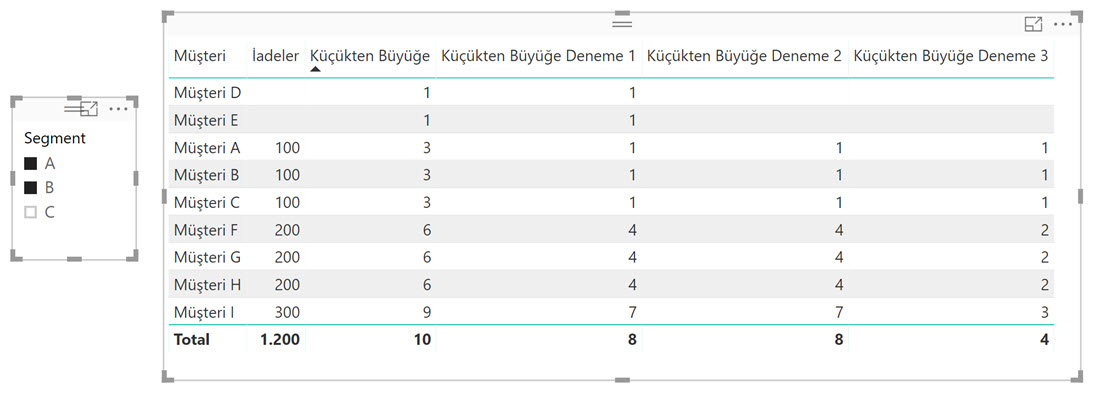
Aynı formülü şöyle de yazabiliriz:
Küçükten Büyüğe Deneme 4 =
IF (
NOT ( ISBLANK ( [İadeler] ) ),
RANKX (
FILTER ( ALLSELECTED ( 'Müşteri İadeleri' ), NOT ( ISBLANK ( [İadeler] ) ) ),
[İadeler],
,
ASC,
DENSE
)
)
İade tutarı sütunu sıfır mı değil mi koşulu yerine [İadeler] metriği boş değilse demiş olduk, aynı kapıya çıkacaktır.
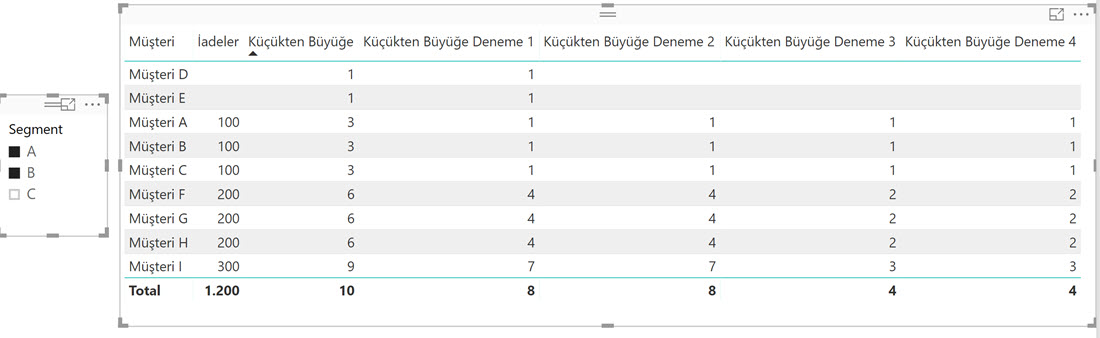
Son bir düzeltme de toplam satırı için yapalım, bu satır için sıralama yapmak manasız!
Küçükten Büyüğe Deneme 5 :=
IF (
HASONEVALUE ( 'Müşteri İadeleri'[Müşteri] );
IF (
NOT ( ISBLANK ( [İadeler] ) );
RANKX (
FILTER ( ALLSELECTED ( 'Müşteri İadeleri' ); NOT ( ISBLANK ( [İadeler] ) ) );
[İadeler];
;
ASC;
DENSE
)
)
)
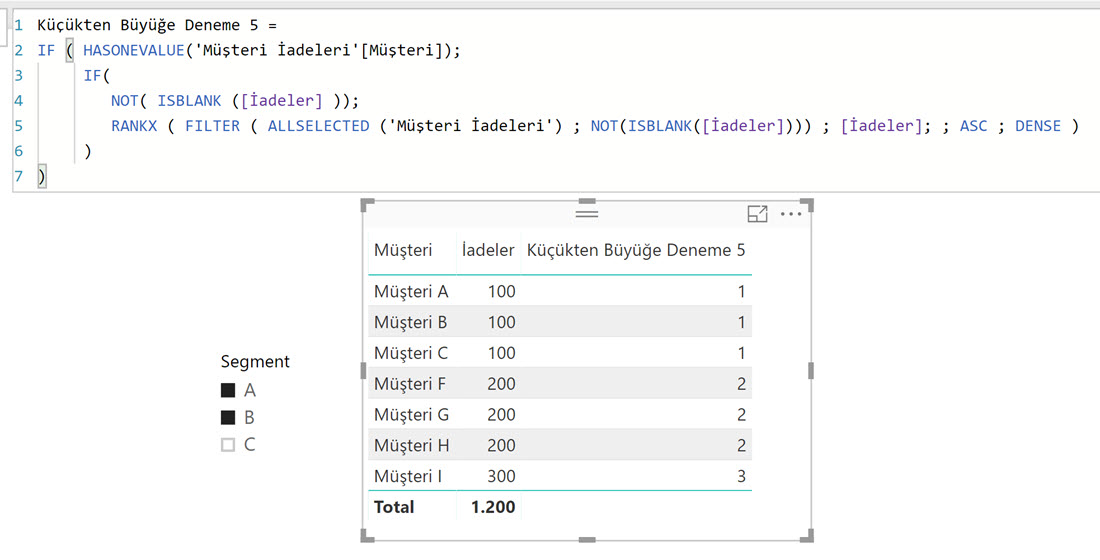
Eşitlik durumunu bozacak bir parametresi yok RANKX’in. Fakat bunu da ufak bir “hileyle” çözebiliriz, RANKX’in sıraladığı [İadeler] metriğinine çok küçük ve her müşteri için farklı olacak bir değer ekleyebiliriz. Tabloda her müşterinin ID’si farklı, bu sütunu bu amaçla kullanabiliriz.
Küçükten Büyüğe Son :=
IF ( HASONEVALUE('Müşteri İadeleri'[Müşteri]);
IF(
NOT( ISBLANK ([İadeler] ));
RANKX ( FILTER ( ALLSELECTED ('Müşteri İadeleri') ; NOT (ISBLANK ([İadeler]))) ;
[İadeler] + DIVIDE ( CALCULATE ( SELECTEDVALUE ('Müşteri İadeleri'[Müşteri ID])) ; 10000 ); ; ASC ; DENSE )
)
)
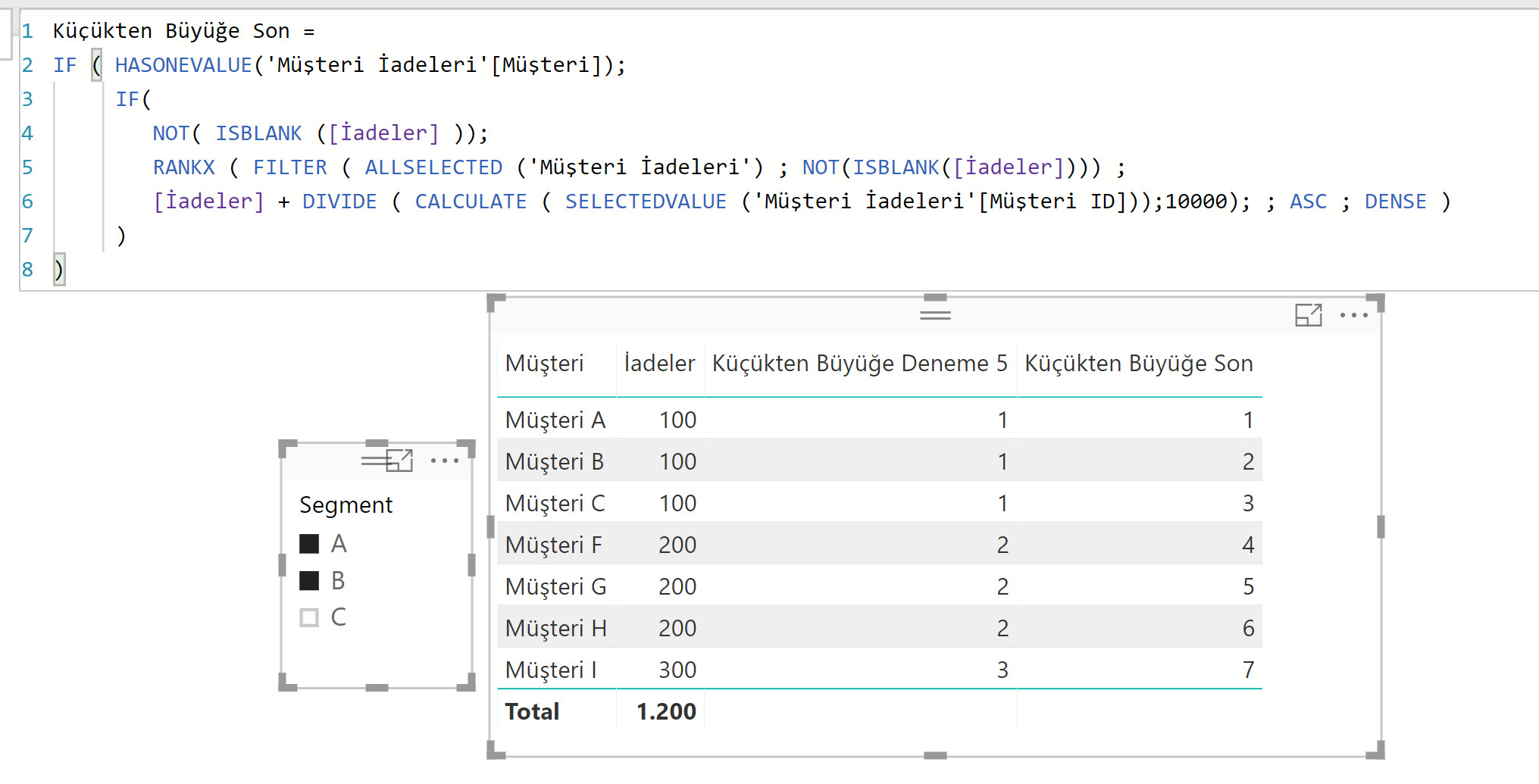
SELECTEDVALUE ‘nun başında niye CALCULATE var için bu yazıdaki olası hatalara göz atabilirsiniz.
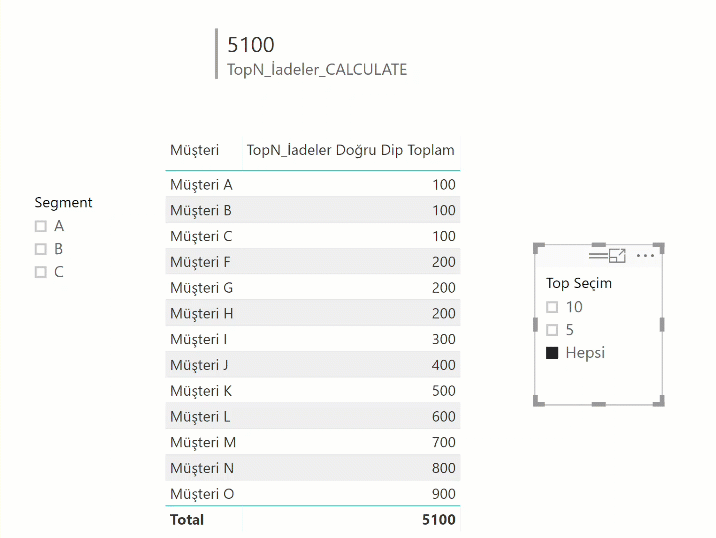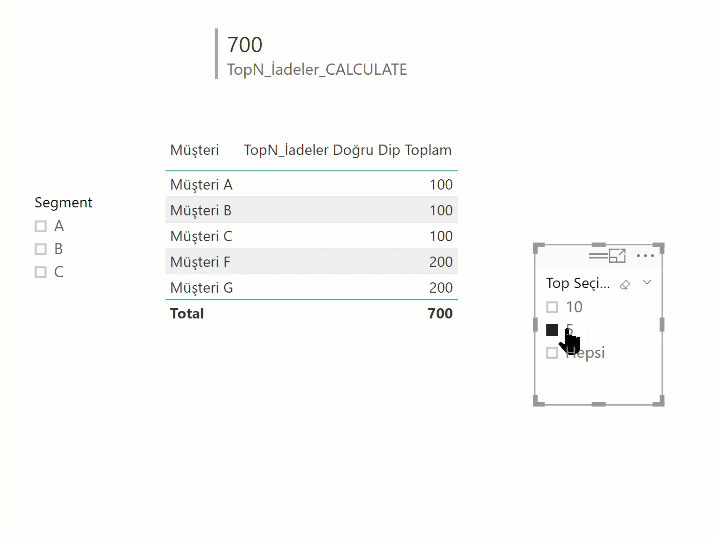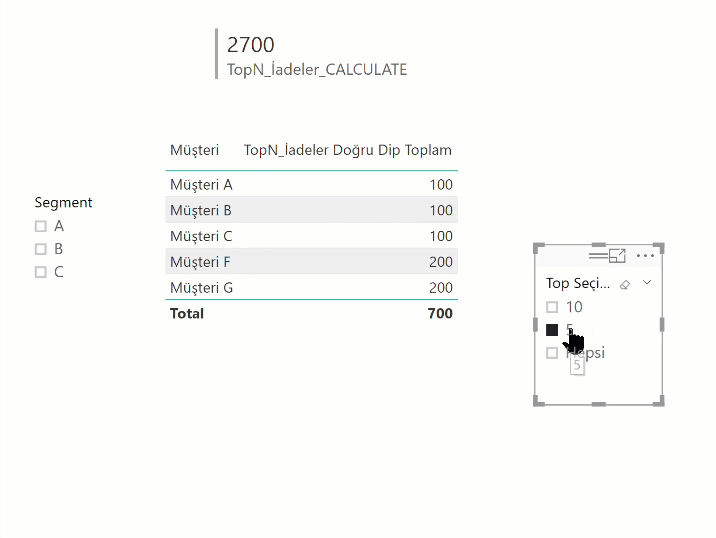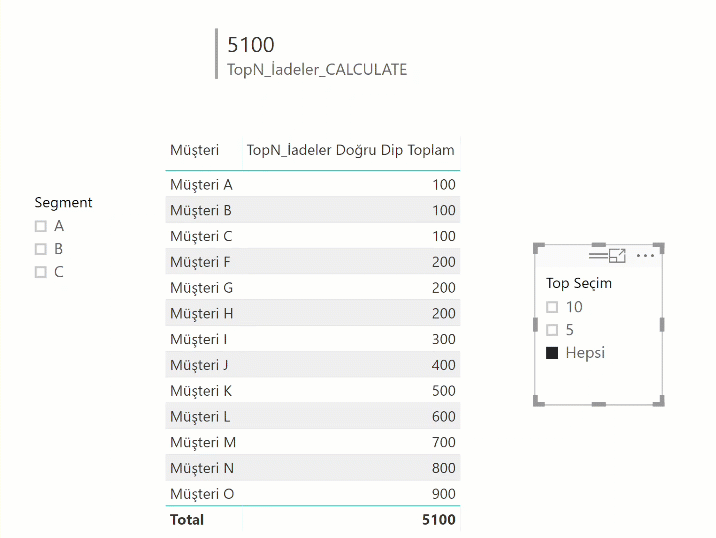
Önceki yazılardakine benzer bir kaç şey daha yapalım: TopN seçimi için bir tablomuz var gene. TopN iadeyi bulalım.
TopN_İadeler :=
VAR Secim =
IF ( HASONEFILTER ('TopSeçim'[Değer]) ;
SELECTEDVALUE('TopSeçim'[Değer]) ;
MAX ('TopSeçim'[Değer])
)
RETURN
SWITCH (TRUE();
[Küçükten Büyüğe Son] <= Secim ; [İadeler]
)
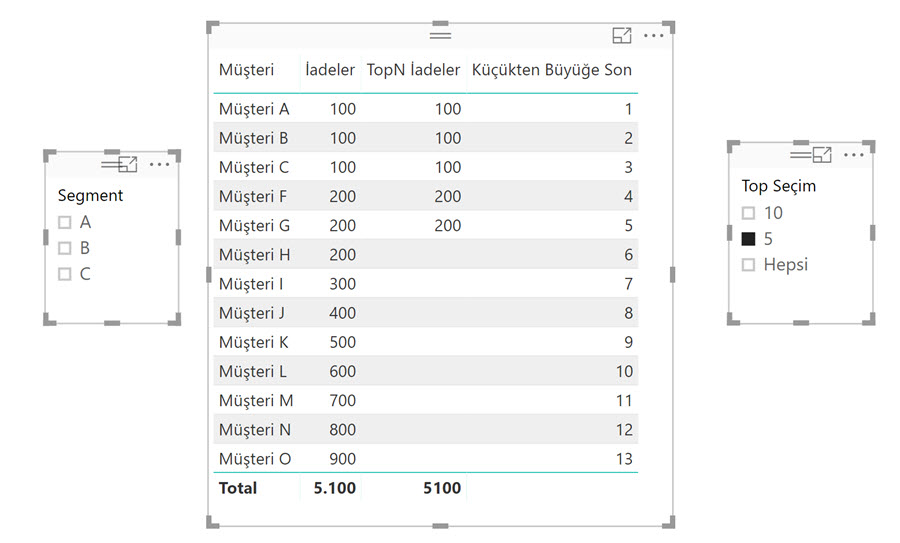
Dip toplamı düzeltelim:
TopN_İadeler Doğru Dip Toplam :=
IF ( HASONEVALUE ('Müşteri İadeleri'[Müşteri]);
[TopN_İadeler];
SUMX ( VALUES ('Müşteri İadeleri'[Müşteri]) ; [TopN_İadeler]
)
)
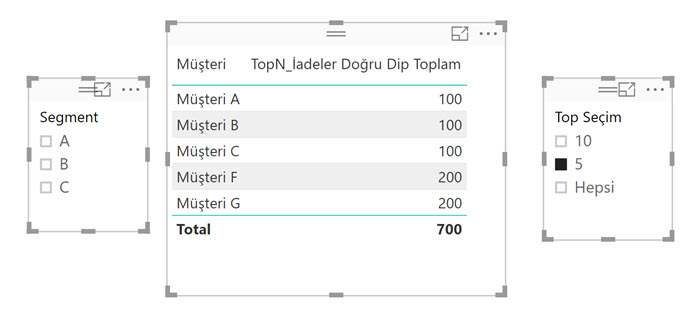
TopN seçimine göre doğrudan toplam iadeyi hesaplamak için aşağıdaki gibi bir metrik de yazabiliriz.
TopN_İadeler_CALCULATE =
CALCULATE (
[İadeler],
FILTER ( 'Müşteri İadeleri', [Küçükten Büyüğe Son] <= [TopN Seçim] )
)
Yazıdaki modeli indirebilirsiniz.
Sadece üyeler görebilir. Hızlı üyelik için sosyal medya hesabınızla giriş yapabilirsiniz!
Yine çok değerli, heyecanla okuduğum bir makale. Çok ince detaylar var. Emekleriniz ve paylaşımlarınız için minnettarım 🙂
Buradaki ” [Küçükten Büyüğe Son] ” metriğini, SQL’deki Row_Number() fonksiyonunun işlevini karşılamak amacıyla kullanabilir miyiz veya buna yönelik bir öneriniz var mıdır? Teşekkürler.
Benzer mantıkta ama veri kaynağında “statik” olarak bir sıralama yaptırmak çok doğru değil bence. Dinamik olarak metrikle çözmek daha kullanışlı. Henüz yazacak fırsat bulamamış olsam da RANKX ‘i hesaplanmış sütun olarak kullanmayı da tercih etmiyorum, bu da statik bir sıralama olacaktır çünkü.
Evet haklısınız, statik olarak kullanmak rapor ara yüzündeki kullanıcı seçimlerine göre her zaman doğru cevap veremeyecektir.
Yukarıdaki ifadem eksik olmuş. Metrik ile dinamik olarak Row_number() işlevini elde edebilmeyi kastetmiştim.
Dynamic Row Number için öneriniz var mıdır? Teşekkür ederim 🙂
Yanlış anlamadıysam böyle bir şey arıyorsunuz.
https://www.sqlbi.com/articles/how-to-compute-index-numbers-at-top-speed/