Power BI ‘da text değerlerle çalışırken, özellikle insan kaynaklarıyla (IK) ilgili modellerde sıklıkla karşıma çıkan bir durum var: Aynı isme hatta aynı başka özelliklere sahip (doğum günü, anne/baba adı gibi) birden fazla personel olabiliyor. Ve tahmin edebileceğiniz gibi aynı isme sahip personelleri herhangi bir görsele düşürdüğünüzde tek bir kişiymiş gibi gözüküyor! Metriklerini de aggregate ederek gösteriyor! Bu tür durumlar için kullanabileceğimiz iki özellik var Power BI ‘da: Row Label ve Key Column!
Ne demek istiyorum!
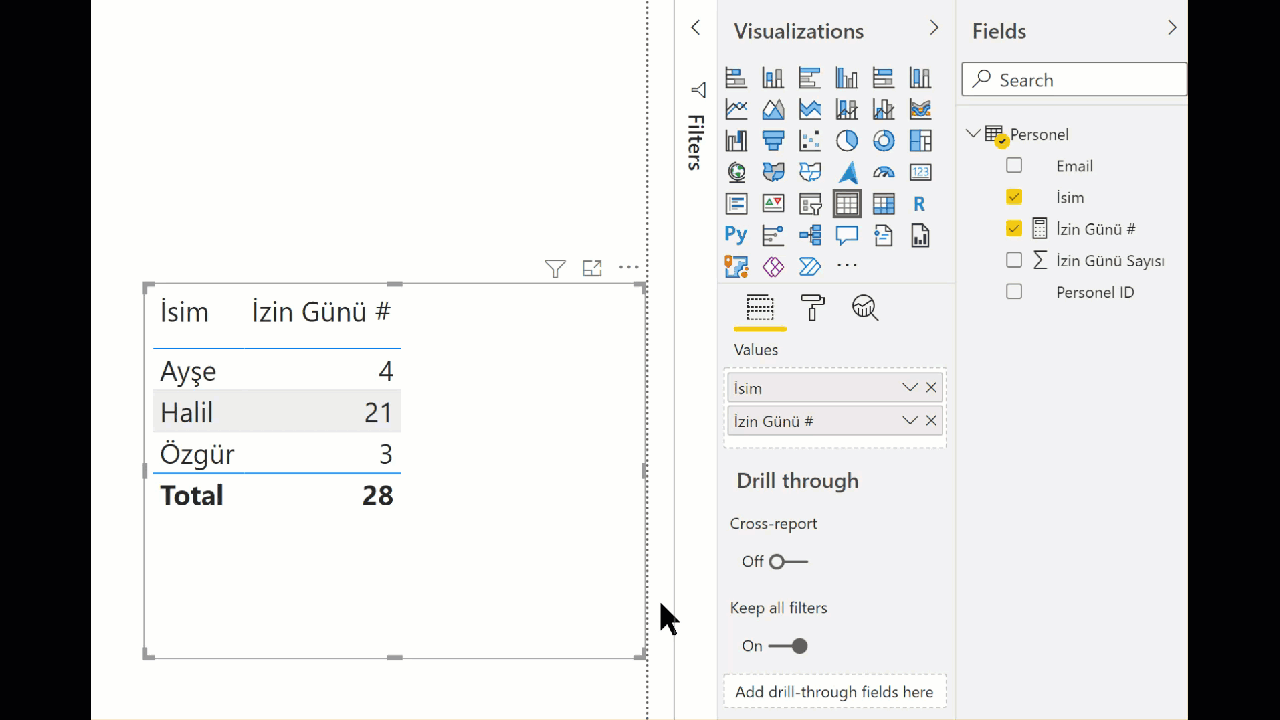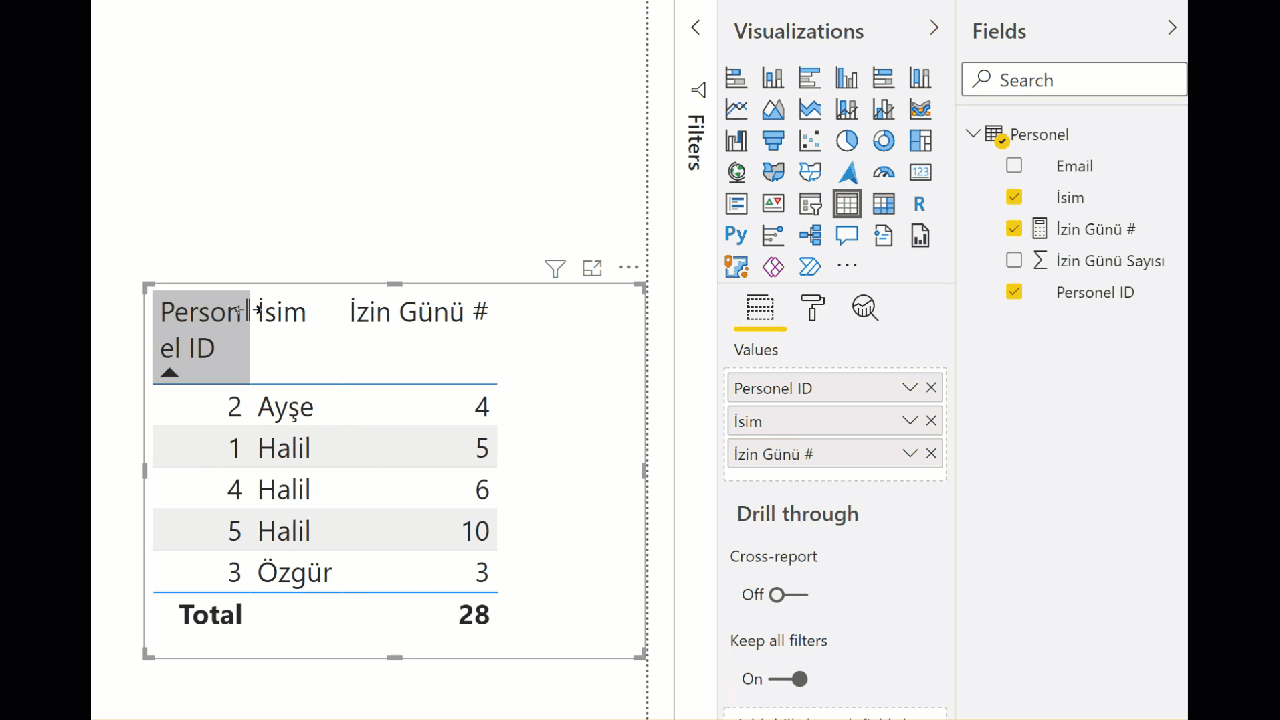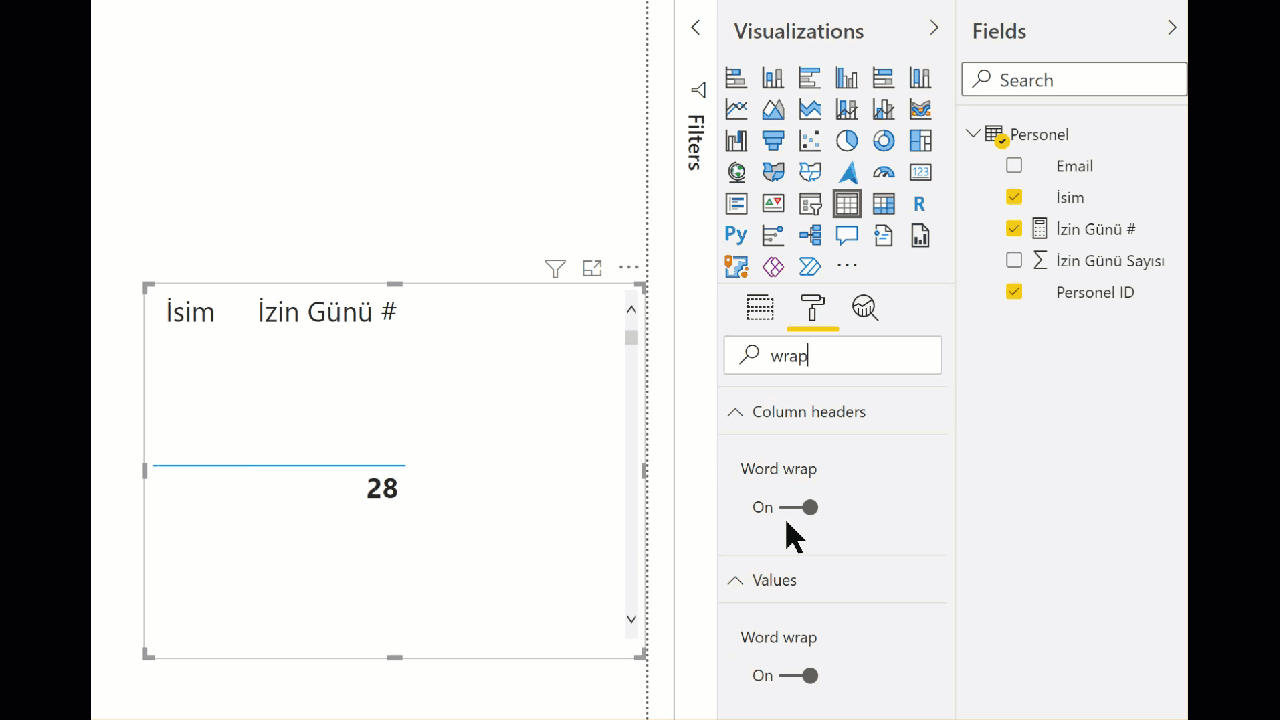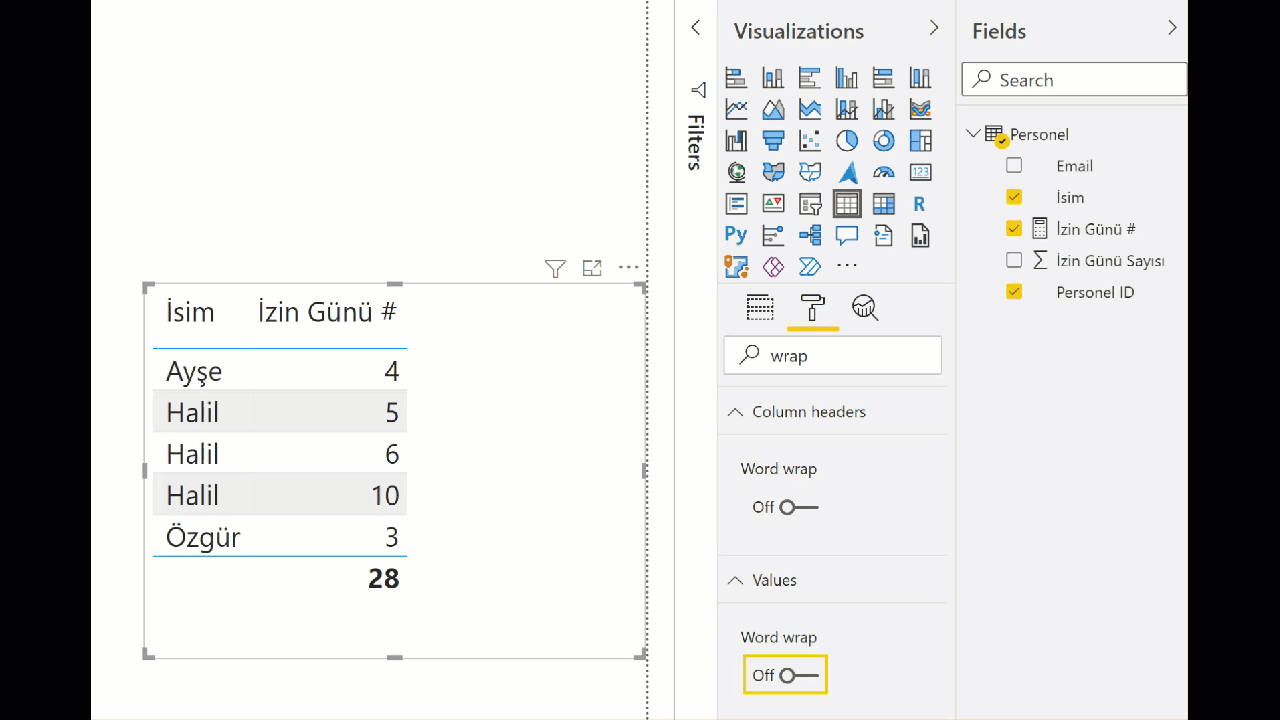
Aşağıdaki gibi basit bir tablomuz var, isim personel ID, email ve izin günü sayısını içeriyor. Resim Power Query ekranından alınma.
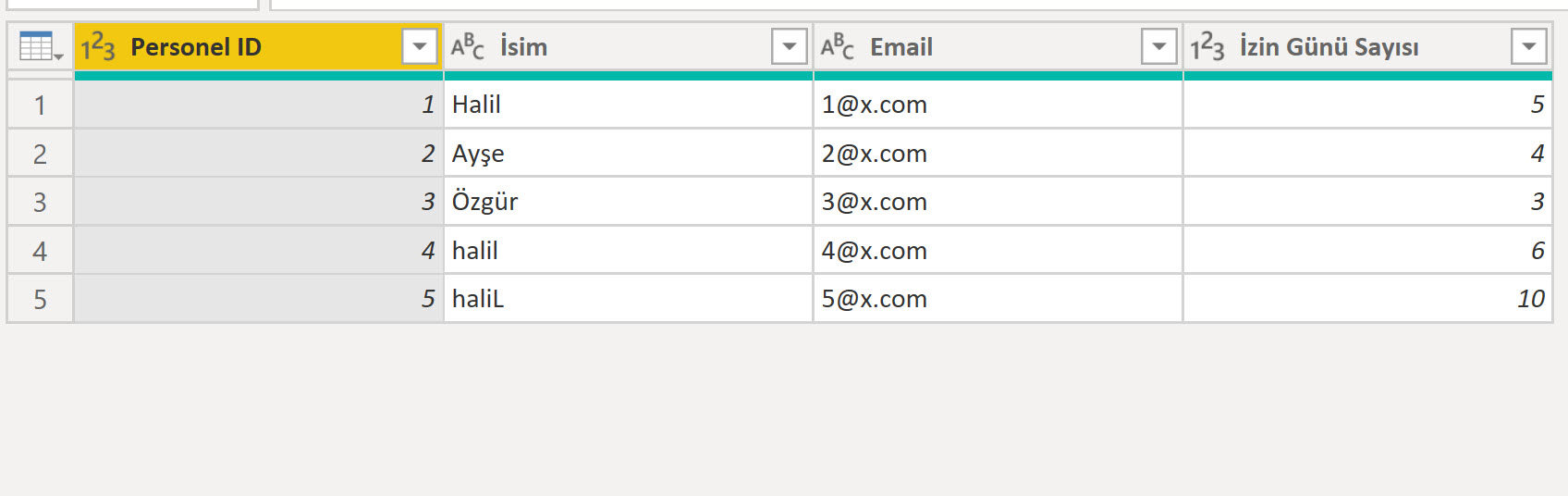
İsimleri aynı fakat ID’leri farklı olan 3 tane “Halil” var. String değerlerinin aynı olmadığına da dikkatinizi çekerim. “H” ile başlayan var, “L” ile biten var, hepsi küçük harf olan var!
İzin günlerini toplayan basit bir de metrik ekleyelim.
İzin Günü # = SUM( Personel[İzin Günü Sayısı] )
İlk “garip” durum desktop tarafında karşımıza çıkıyor!
Power Query’de farklı string değerleri olmasına rağmen desktop’a aktardığımızda hepsini “aynı hizaya” sokuyor”!
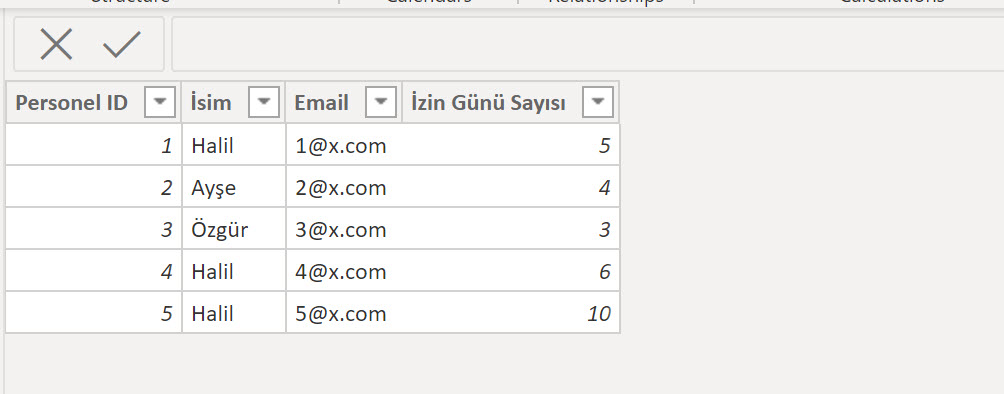
Peki hangi hizaya soktu? Niye hepsini “Halil” yaptı da “halil” yapmadı, buna birazdan geleceğim, önce asıl sorunumuzu çözelim!
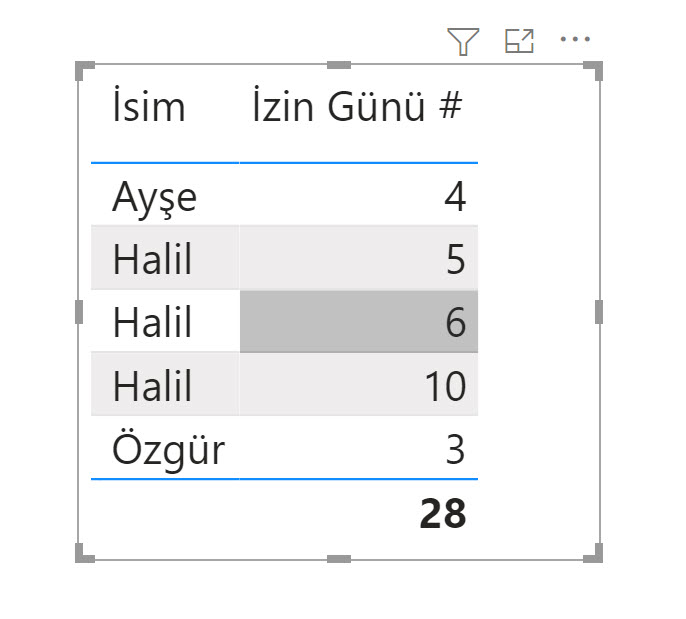
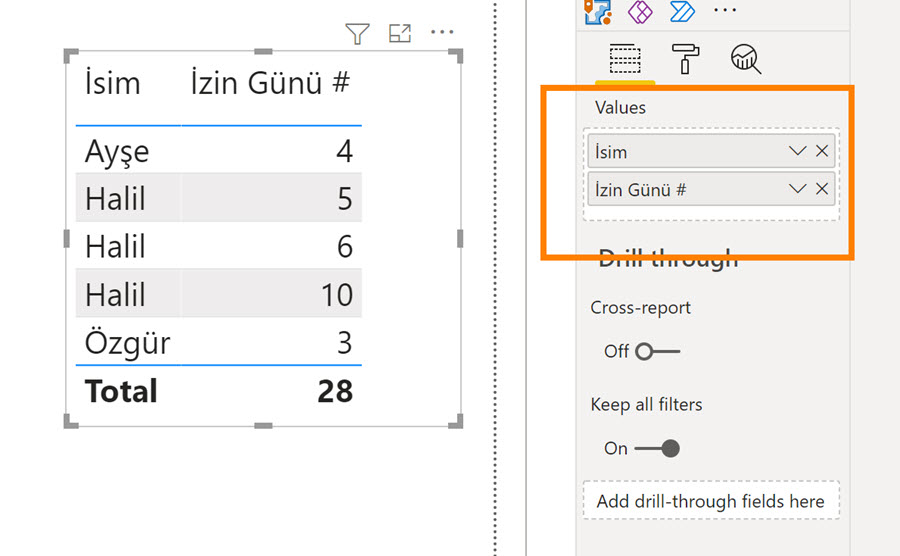
İsim sütununu metrikle birlikte bir matrise düşürüyorum.
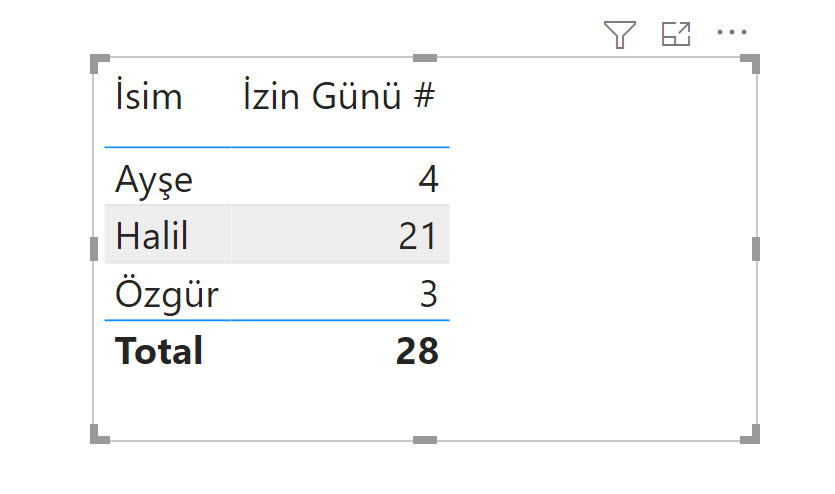
Büyük harf küçük harf demeden tüm Halil’leri topladı, tek bir kişiymiş gibi gösteriyor! Oysa 3 farklı kişi var.
Bunu çözmek için ilk akla gelen yöntem, “Personel ID” sütununu da matrise düşürüp daha sonra bu ID sütununu gizlemek olurdu muhtemelen. Çünkü ID sütunu sadece tekil değerler içeriyor.
** Animasyonu görmek için resmi tıklamalısınız!
Evet bu numara işe yarıyor, hatta asimetrik rapor üretmek için -şu anda- kullanılabilecek tek yöntem gibi.
Fakat daha doğru olan asıl yöntem, ilişkiler panosundaki tablo özelliklerinden Row Label ve Key Column alanlarını kullanmak! İlişkiler panosundayken tabloyu seçtiğinizde “Properties” ekranı çıkacaktır. Buradaki “General” sekmesini de açarsanız bu alanları görebilirsiniz.
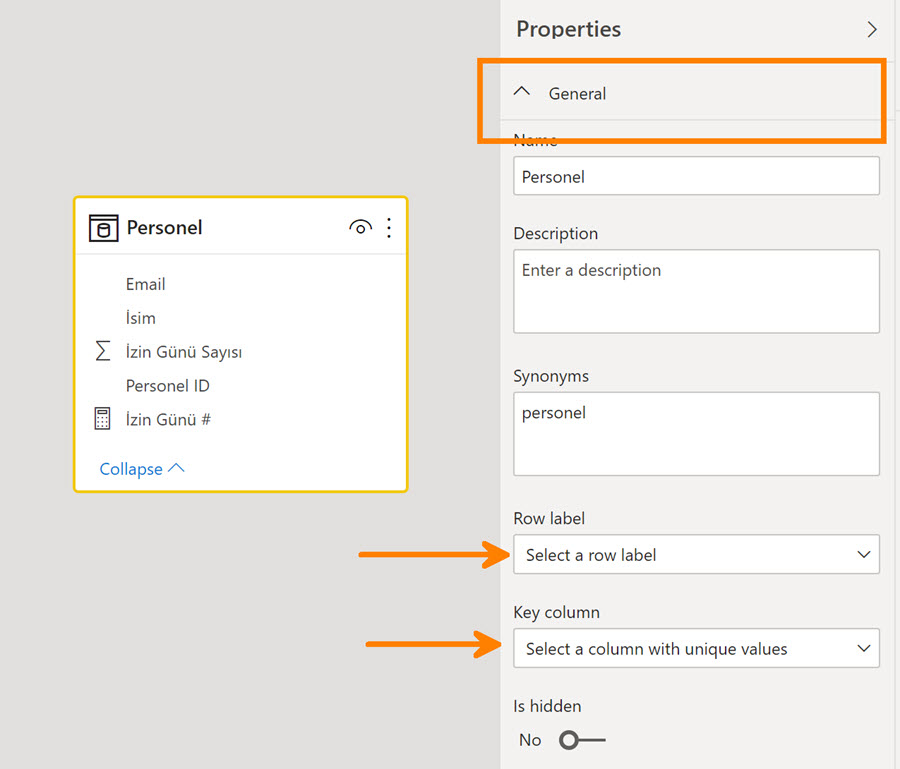
“Key Column” adı üstünde, tablodaki tekil değerler içeren anahtar sütun. Row Label için de İsim sütununu seçiyorum.
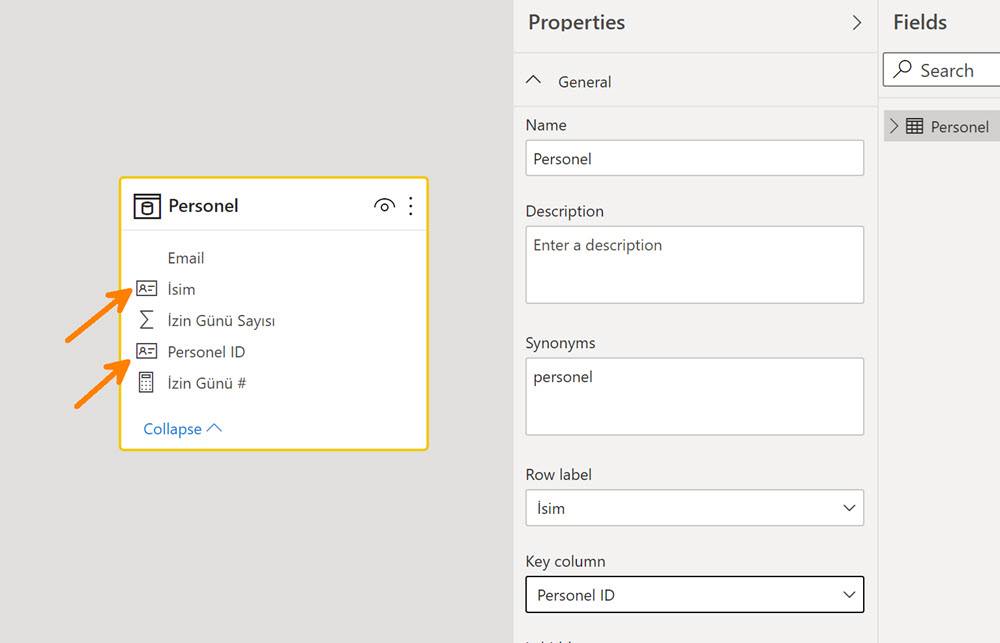
Bu seçimleri yapınca İsim ve Personel ID sütunlarının yanında küçük bir kimlik kartına benzeyen bir ikon beliriyor. Bu seçimler bir nevi ilgili tablonun master entity‘si neyse onu tanımlamamızı sağlıyor: Anahtar sütunum Personel ID, tablonun asıl elemanı da personelin ismi. Gibi.
Artık yukarıdaki gibi Personel ID’yi düşür-gizle numarasına ihtiyacımız yok, her bir isim, string değerleri aynı olsa bile, ID’leri farklı olduğu için ayrı birer entity gibi algılanıyor.
…
Yukarıdaki “peki hangi hizaya soktu” cümlesinden devam edelim!
Her dilin yaratıcıları -by design- karar veriyor, formül dili + string değerler büyük harf küçük harf duyarlı mı olsun yoksa olmasın mı? Farklı dillerin farklı seçimleri var.
Power BI için değerlendirecek olursak: DAX case-insensitive bir dil. Hem formül dili hem de string karşılaştırmasında, harf aynı ise büyük ya da küçük yazılmasına aldırış etmiyor! Yukarıdaki basit metriği büyük harf “SUM” ile değil “sum” ile yazsanız da kabul eder. Büyük harf ile fonksiyonları yazmak sadece genel kabul görmüş bir uygulama. Aynı şey string değerler için de geçerli DAX’ta.
“Halil”, “halil”, “haliL” hepsi aynı değer DAX için.
DAX’ta fonksiyon olarak string karşılaştırması yaparken büyük-küçük harf duyarlı tek fonksiyon FIND. Tabii string değerler uygun şekilde desktop tarafına geldiyse.
DAX tarafını şöyle bitirelim: Eğer Power BI Desktop veya Azure Analysis Service ile çalışıyorsanız DAX tarafı komple case-insensitive, yani büyük-küçük harf duyarsız.
Eğer on-prem SQL Analysis Service ile çalışıyorsanız bu kurulumunuza bağlı, “collation” olarak case-sensitive seçebilirsiniz, ama varsayılan (default) değer case-insensitive kurulum.
Power Query ‘ye gelecek olursak : Formül dili M de dahil olmak üzere burası tamamen case-sensitive, yani büyük harf-küçük harf duyarlı! İçinde “if” geçen bir formülü “IF” olarak yazmaya kalkarsanız hata mesajı verir. M formül diline aslında şöyle desek daha doğru, fonksiyonun yazılışı neyse o, başka bir yazım tipi kullanamazsınız.
Table.Distinct (…) çalışır. Table.distinct (…) çalışmaz!
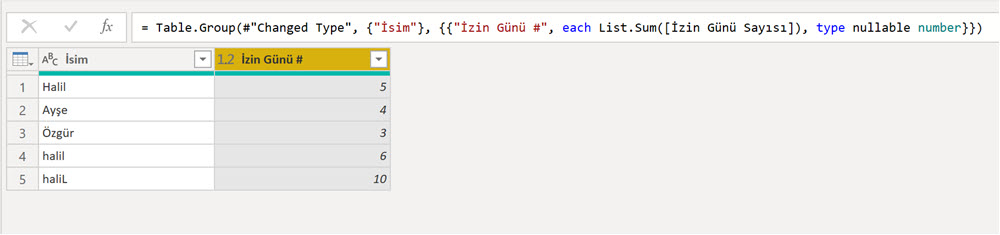
String değerler de benzer şekilde case-sensitive PQ tarafında. Desktop tarafına aktardığımızda hepsi “Halil” gözüken değerler, Power Query tarafında farklı gözükür ve her farklı değer ayrı sayılır. Örneğin ilk resimdeki datayı “İsim” sütünu üzerinden grupladığımızda her bir değer ayrı gözükür!
…
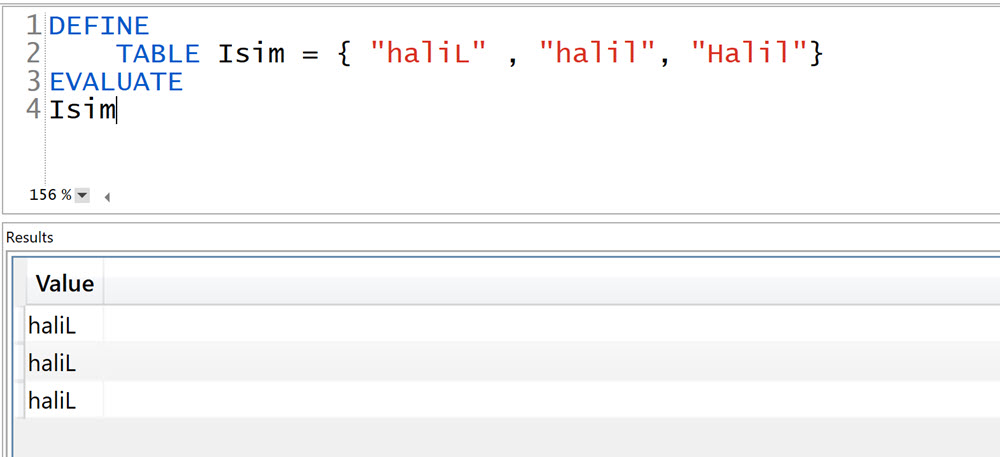
Peki niye desktop tarafına aktardığımızda “Halil” olarak gösteriyor hepsini de “halil” demiyor? Bu da tabular modelin veriyi tutan/saklayan kısmı “Vertipaq” motoru (engine) ile ilgili bir tasarım kararı! Yazıdaki örneğe göre İsim sütunundaki değerler “Halil”, “halil”, “haliL” sırasıyla gidiyor. İlk sırada okuğu değeri bir integer (tamsayı) ile eşleştirdikten sonra, sonraki büyük-küçük harf farketmez tüm aynı değerleri aynı integer sayı ile eşleştiriyor. Eğer veride ilk sırada “halil” gözükseydi tüm string değerlerini “halil” yapacaktı!
Bunu da DAX Studio ile örneklendirmek mümkün.
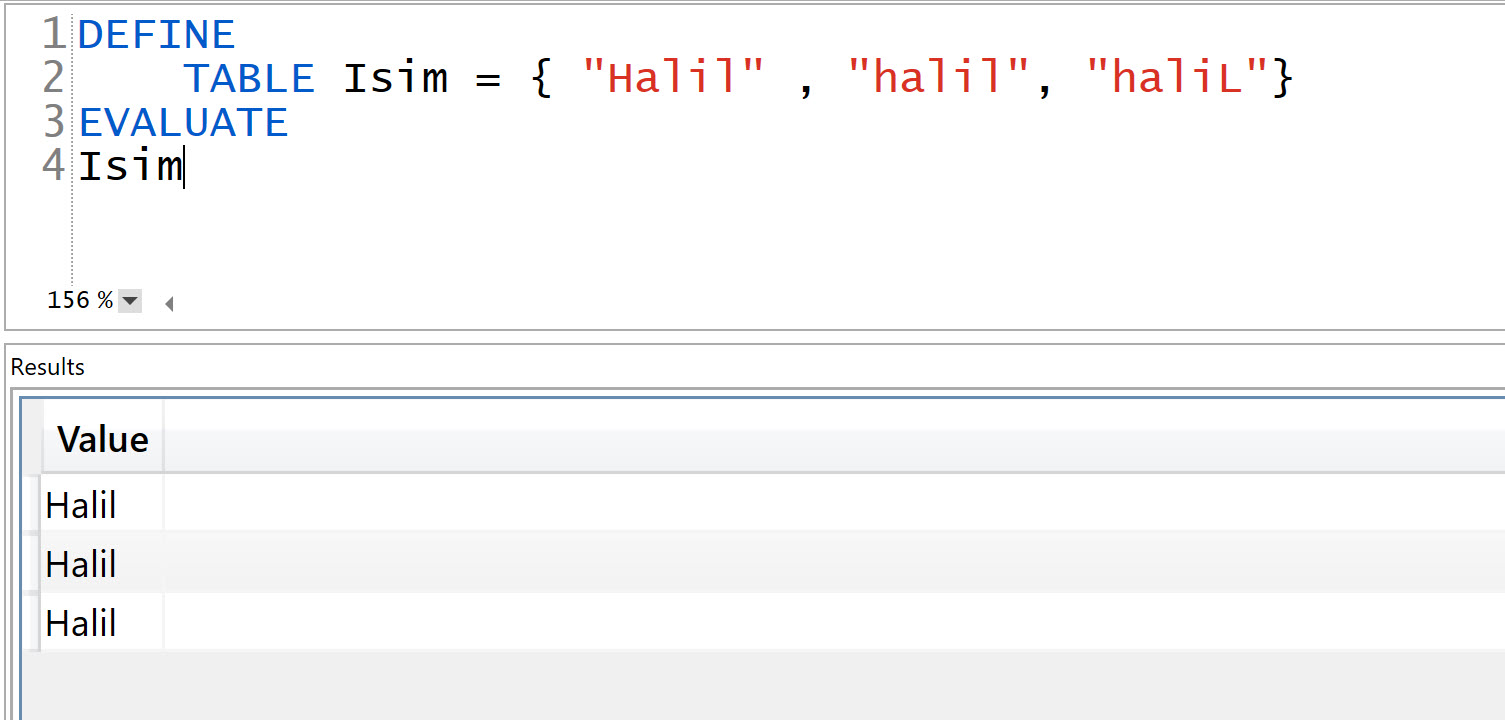
İlk sırada hangi değer gözüküyorsa onunla devam ediyor!
Yazıdaki modeli indirebilirsiniz.