Power BI projelerinin en önemli kısmı veri modelinin doğru tasarlanması. Yanlış/hatalı veri modeli üzerinde DAX’ı ne kadar iyi bilirsek bilelim taklalar atmak bir noktadan sonra zor. Doğru veri modelini kurmak -özellikle tek bir fact tablosunun olduğu modellerde- çok zor değil, her şey dönüp dolaşıp star şemaya – veya snowflake şemaya – bağlanıyor. Bunlara ek olarak, çift yönlü ilişkiler gibi (bi-directional) sadece Power BI’a özgü teknikleri ve köprü tablosu gibi jargonda olan yöntemleri bilmek de önemli.
Bazı ERP’lerin tasarımına bağlı olarak özellikle boyutlandırmaya ilişkin farklı yapıları var ve bunları modellemenin genelde birden fazla yolu mevcut. Aşağıdaki örnek veriler Microsoft ERP uygulamalarından olan Navision ‘dan alınma. Daha doğrusu Navision yapısındaki bir veri seti. Gene Microsoft’un Axapta’sında da benzer bir yapı var.
Benzer tasarımı başka bir kaç ERP’de de gördüm, JD Edwards gibi Oracle uygulamalarında da benzer bir boyutlandırma mantığı kurulmuş, muhtemelen daha da fazla sayıda ERP’de benzer tasarımlar vardır.
Veri seti şu şekilde:
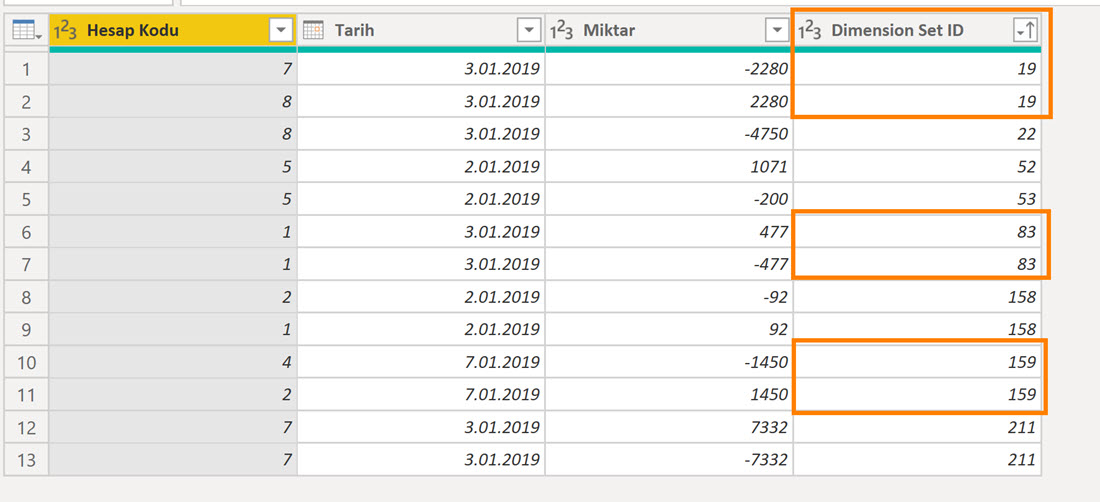
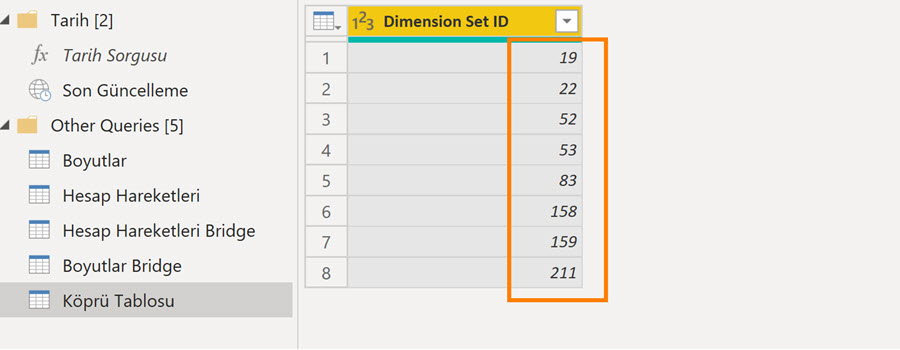
Örnek hesap hareketleri tablosunda, satırdaki kaydı boyutlandırmak için bir Dimension Set ID sütunu kullanılmış. Aynı numara birden fazla transaction’da geçebiliyor; 19, 83, 158, 159 vs … gibi.
İlgili boyut numaralarının tutulduğu tablosun yapısı ise aşağıdaki gibi:
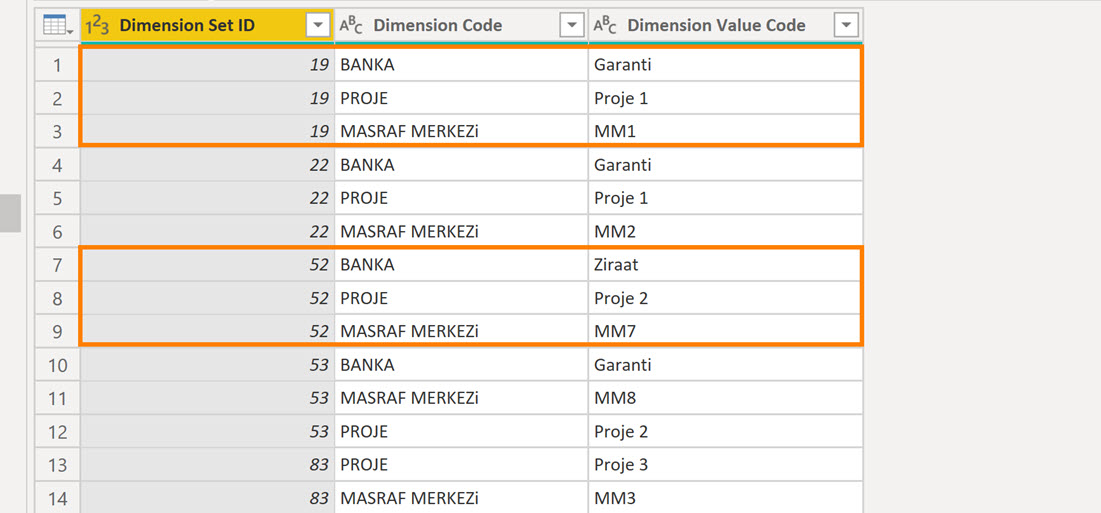
Her bir ID farklı boyut kombinasyonlarını tutacak şekilde satırlarda tekrarlanıyor.
** Sütun isimlerini Navision kullanan vardır belki diye değiştirmedim, bu tablo Navision’daki Dimension Set Entry tablosu, hareketlerin olduğu tablo ise GL Entry tablosu.
Her iki tabloyu Dimension Set ID üzerinden nasıl bağlayacağız?
** Her iki tabloyu da many-to-many ilişki tipiyle Dimension Set ID üzerinden ilişkilendirelim geçelim demeyeceğim, çünkü many-to-many ile ilgili anlatılması gereken epey detay var ve bu veri seti tam uygun bir örnek değil. Veri modelinin sırf tasarımına ilişkin yazmayı planladığım seride bahsedeceğim bu konudan.
Power BI ‘da iki tablo arasında ilişki kurmanın belli kuralları var. Varsayılan ilişki tipinin one-to-many (ya da many-to-one) olduğunu düşünecek olursak – ki herhangi bir modelde bize lazım olan ilişkilerin 99% ‘u one-to-many’dir- , ilişkinin one tarafındaki tablo sadece ve sadece tekil değerleri içerebilir, her iki tabloda da ilişki kurulacak sütunun veri tipi aynı olmak zorundadır. (Sütun isimleri farklı olabilir.) Ve iki tablo arasında ilişki tek sütun üzerinden kurulur. (Bu bir kısıtmış gibi gözükse de değil aslında, kompozit anahtar kullanabiliriz.)
One-to-many üzerinden ilişki kurmak istiyorsak bize tekil değerleri içeren bir tablo lazım: hesap hareketleri tablosunu tekil ID’ler içerecek şekilde değiştiremeyiz, manasız olur, fakat boyut tablosundaki ID’leri kolaylıkla tekilleştirebiliriz!
Yapmamız gereken şey, her bir satırda tek bir ID olacak şekilde, ilgili ID’nin çoklayan satırlarındaki boyut kodlarını -değerleriyle birlikte- sütunlara taşımak!
Yani aşağıdaki gibi tabloyu değiştirmeliyiz:
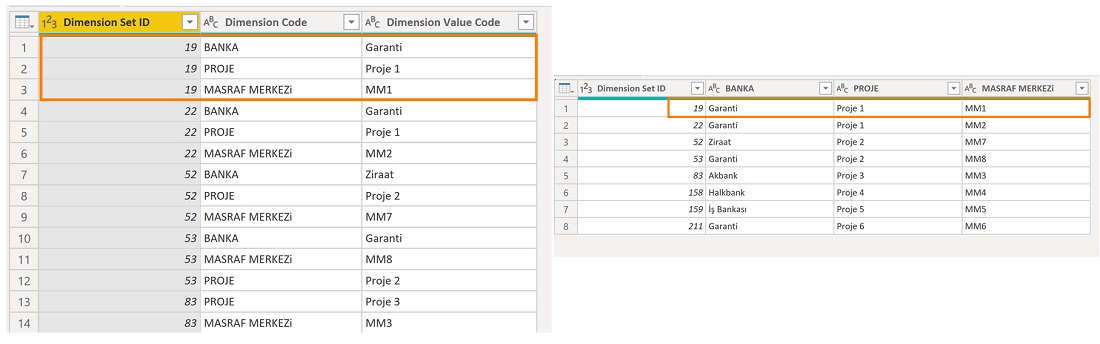
ID 19’u örneklendirmek gerekirse : BANKA, PROJE ve MASRAF MERKEZİ boyutlarıyla 3 satır olan yapıyı, tek bir satıra BANKA, PROJE ve MASRAF MERKEZİ sütunları olacak şekilde çevirmeliyiz.
Bunu yapabileceğimiz en kolay ve en etkili yer Power Query ve bu transformasyonun adı PIVOT yapmak!
Power Query tarafında Dimension Code sütunu seçiliyken -çünkü yeni oluşacak sütunların isimleri buradan gelecek- menüden “Pivot Column” ‘u tıklıyorum.
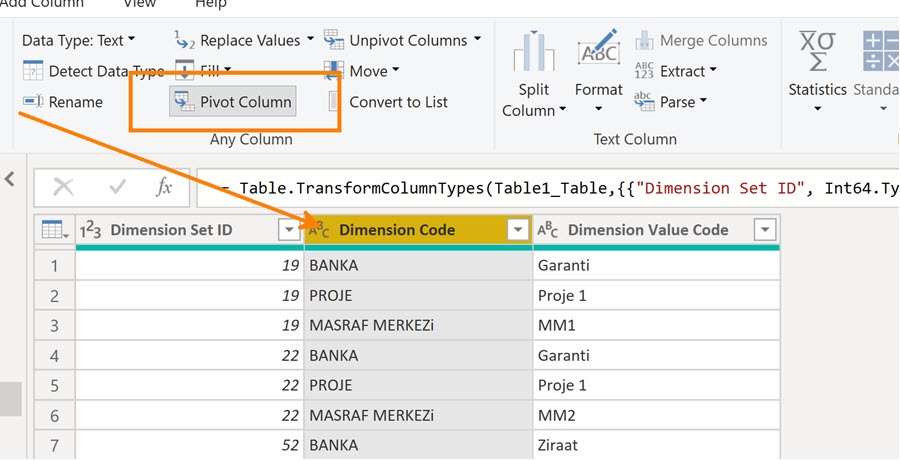
Açılan menüde neleri seçtiğimiz önemli :
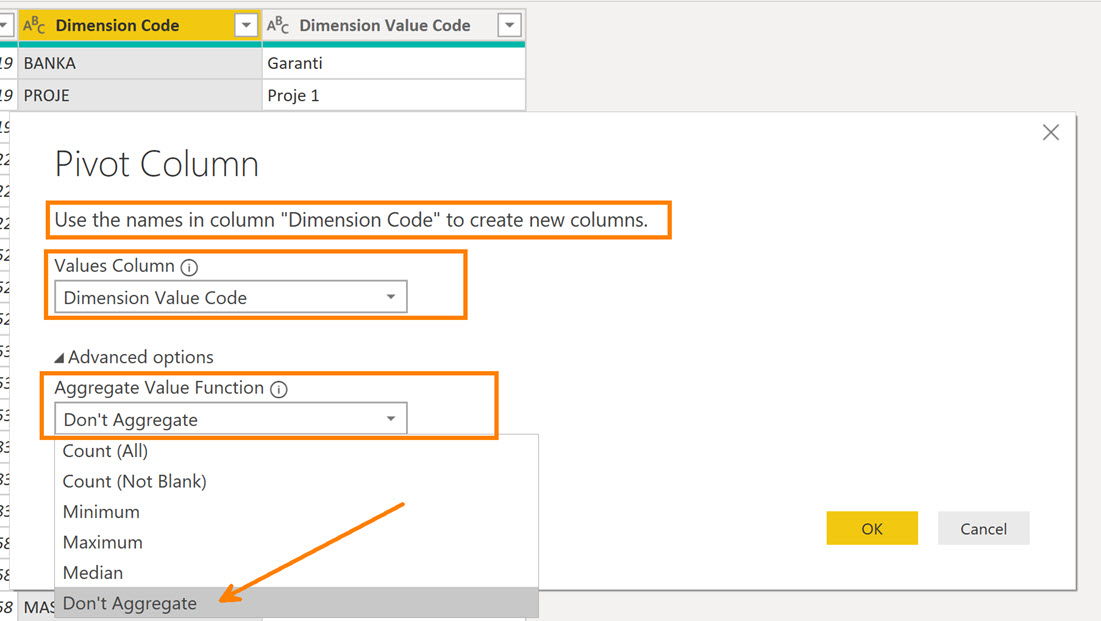
Pivota (yani sütunlara) alacağımız boyutların isimleri Dimension Code sütunundaki değerlerden gelecek, BANKA, PROJE gibi.
Bu oluşan sütunların değerleri Dimension Value Code sütunundan gelecek ve gelen bu değerleri aggregate etmeyeceğiz.
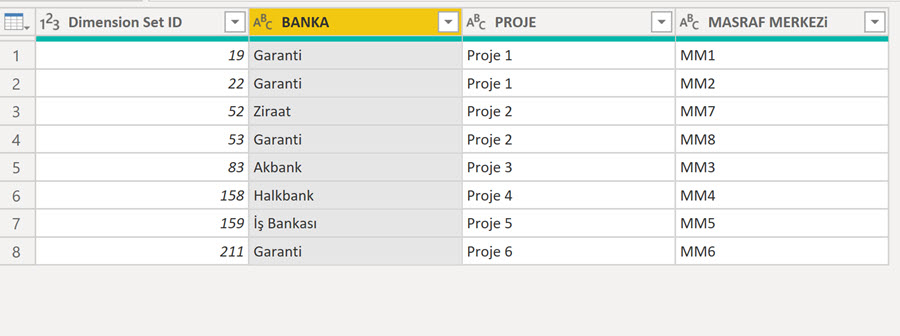
İki tabloyu artık Dimension Set ID üzerinden bağlayabiliriz.
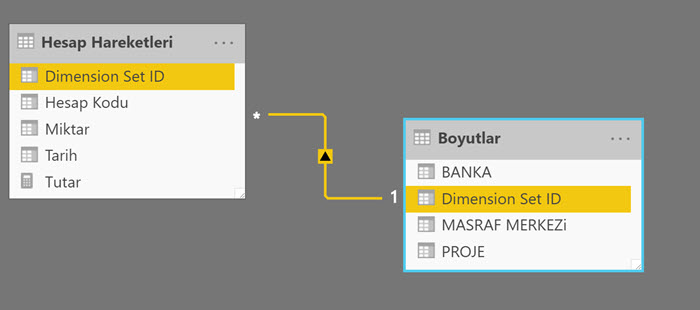
Ara not : Boyut tablosundaki BANKA, PROJE vs sütunlarının değerleri anlamı açık birer text değil de başka kodlar ise, bu tabloya bağlantı yapmak üzere ilgili boyutların anlamlarını içeren master tabloların da olması gerekebilir. Artık ya ilişki kurarız, ya da kod açıklamalarını “merge” ederek boyut tablosuna getiririz.
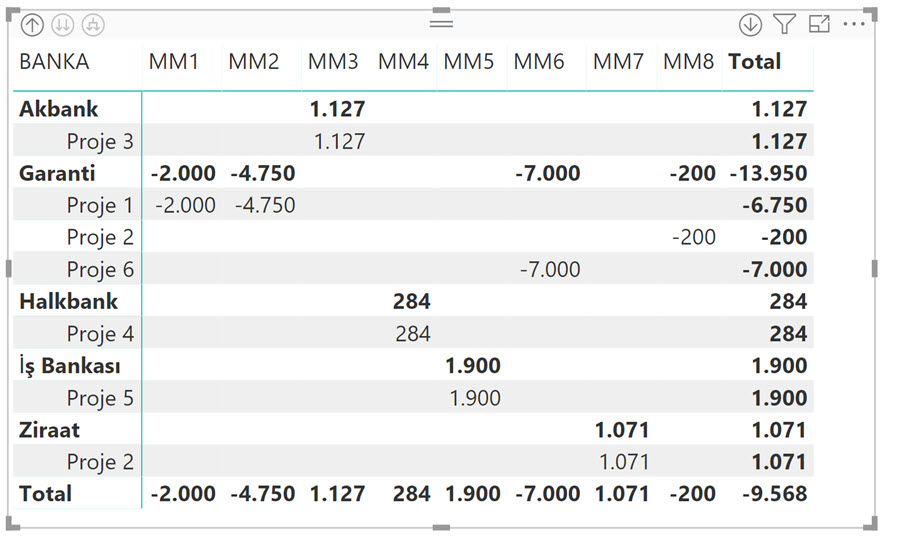
Bu tasarımın avantajı şu, boyut isimleri “Boyutlar” tablosunda ayrı birer sütun olarak duruyor, dolayısıyla son kullanıcı ilgili sütunları rahatlıkla anlayabilir, alt alta bir hiyerarşi olacak şekilde dilediğinde kolaylıkla görselleştirebilir, satıra sütuna (eksene) koyabilir. Kullanımı kolay!
…
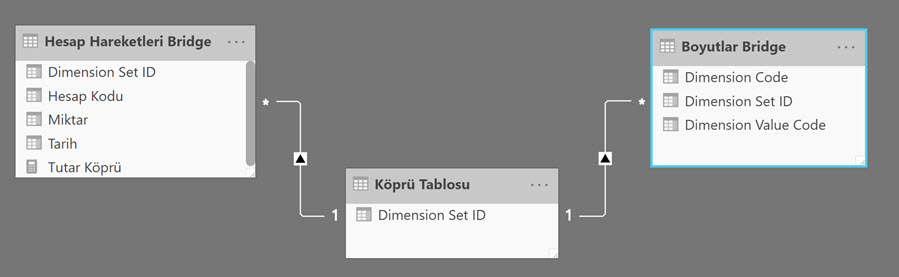
Diğer bir yönteme gelince, iki tablo arasına, sadece tekil ID değerleri içeren bir üçüncü köprü tablosu (bridge table) koyabiliriz.
Köprü tablosu, her iki tabloyla da ilişkilendirebileceğimiz şekilde tek bir sütundan oluşuyor ve sütundaki ID’ler tekil.
Köprü tablosunu oluşturmak -gene Power Query tarafında- son derece kolay: Boyut tablosunu kopyalayarak (duplike ederek) yeni bir tablo yarat, ID sütunu haricinde diğer tüm sütunları uçur, en sonunda da bu sütundaki duplike değerleri uçur, elde tekil değerleri içeren tek bir sütun kalsın!
İlişkileri kuracak şartları oluşturduk, tabloları ilişkilendirebiliriz!
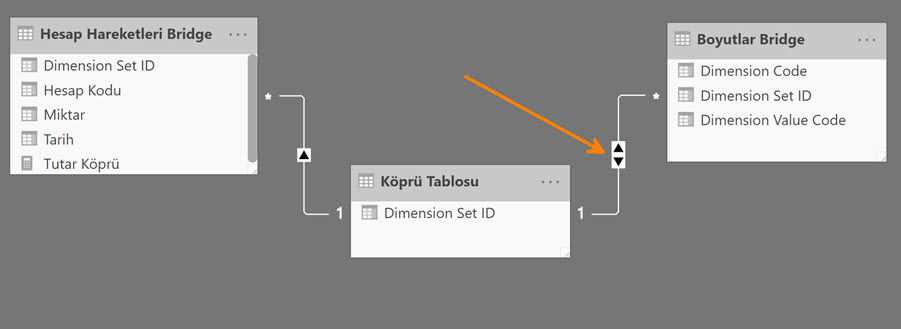
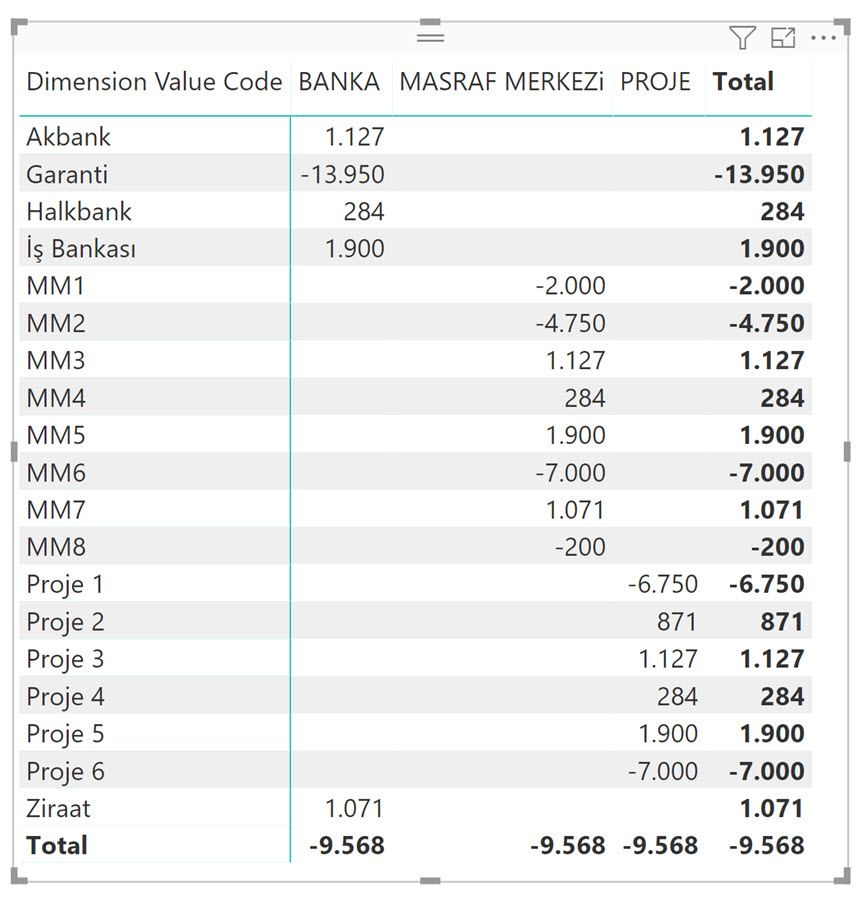
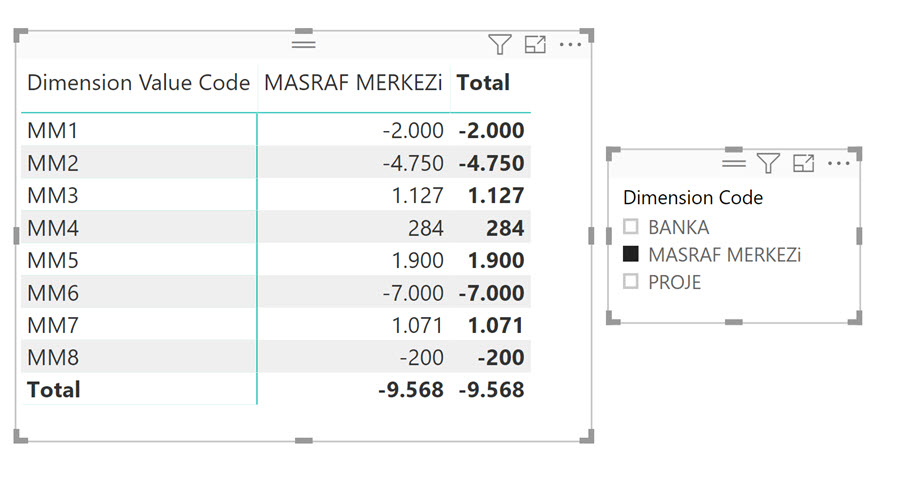
Raporları sadece Dimension Set ID üzerinden tasarlayacak olsaydık bu tasarım gayet güzel çalışabilirdi! (Bakınız Birden Fazla Tabloyu Ortak Sütun Üzerinden Bağlamak) Fakat bu haliyle boyutları kendi içerisinde kırmak mümkün değil! Filtreler boyut tablosuna doğru tek yönlü akıyor! Dolayısıyla -misal- aşağıdaki gibi bir matris oluşacaktır.

Her yerde aynı rakam var!
Doğru çalışması için, köprü tablosuyla boyut tablosu arasındaki ilişkiyi çift yönlü yapmalıyız!
Ancak o zaman doğru çalışacaktır.
Bu tasarımın avantajı da tek bir boyut kodu sütunu üzerinden, başka sütunlarla uğraşmadan görselleri istediğimiz gibi görüntüleyebiliyor olmak! Eğer buna benzer bir modelde çok fazla sayıda boyut varsa ve çok sayıda sütunun kafa karıştıracağını düşünüyorsanız tercih sebebi olabilir. Her iki tasarımı da kullandığım Navision projeleri oldu. İhtiyaca ve kullanım kolaylığına göre karar vermek lazım.
Çift yönlü ilişkilerle ilgili okumak isterseniz bu yazıya göz atabilirsiniz.
** Çift yönlü ilişkileri -genellikle- kalıcı yapmamanızı öneriyorum ama bu şablon için kalıcı ilişki daha uygun.
Son olarak, köprü tablosu yönteminin farklı şekillerde kullanımı olabilir. En çok kullanıldığı yer ise many-to-many ilişkilerdeki -olası- performans probleminin önünde geçmek ve many-to-many ‘yi -many-to-many ilişki kurmadan- modelleyebilmek.
Yazıdaki modeli indirebilirsiniz.
Sadece üyeler görebilir. Hızlı üyelik için sosyal medya hesabınızla giriş yapabilirsiniz!