Her veri modelinde en az bir tane fact tablosu olur. Tüm fact tabloları genel olarak iki farklı tipte sütun içerir: entity’lerin (varlıkların) ID’lerini içeren anahtar sütunlar ve üzerinde hesap kitap (aggregation) yapacağımız nümerik sütunlar. Genel bir yaklaşım olarak, her farklı tip aggragetion için ayrı ayrı nümerik sütunlar olur. Satış tutarı mı var? Ayrı sütun! Maliyet mi var? Ayrı sütun! Gibi. Bu nümerik sütunları boyut olarak tasarlamak bir modelleme yaklaşımı olarak bazen avantaj sağlayabilir. (Bu, bazen de sağlamaz anlamına geliyor aynı zamanda!)
Tipik bir fact tablosu görünümü:
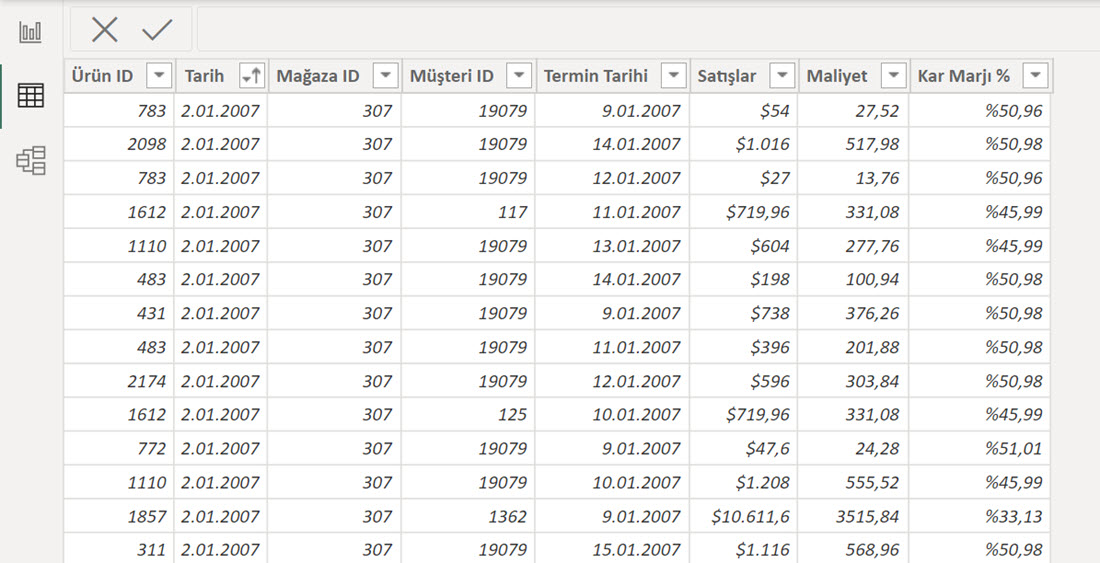
Ürün, Mağaza, Müşteri, Tarih, Termin sütunları ID’leri içeren anahtar sütunlar, diğerleri de üzerinde işlem yapacağımız nümerik sütunlar.
Yazı İçeriği
* Veri modeline yeni başlayanlar için ara not: Tarih bilgisi (bazen fact tabloları birden fazla tarih sütunu içerebilir), öyle değilmiş gibi bir izlenim verse de, aynen Ürün gibi, aynen Müşteri gibi bir entity’dir. Dolayısıyla her modelde mutlaka bir tarih master tablosu olması gerekir.
Eğer nümerik sütunlarınız transactional veri içeriyorsa SUM, AVERAGE gibi basit aggregation’lar -genelde- sorunsuz çalışır. Snapshot veriyle çalışıyorsanız, yazmanız gereken gereken formüllerin mantığı snapshot verinin yapısına göre değişebilir.
Nümerik Sütunları Boyut Olarak Tasarlamak Ne Demek?
Basitçe, anahtar sütunları sabit tutup, diğer geri kalan nümerik sütunları unpivot yapmak demek!
Yukarıdaki tablonun nümerik sütunlarını unpivot ettiğimizde aşağıdaki şekle sokmuş oluruz.
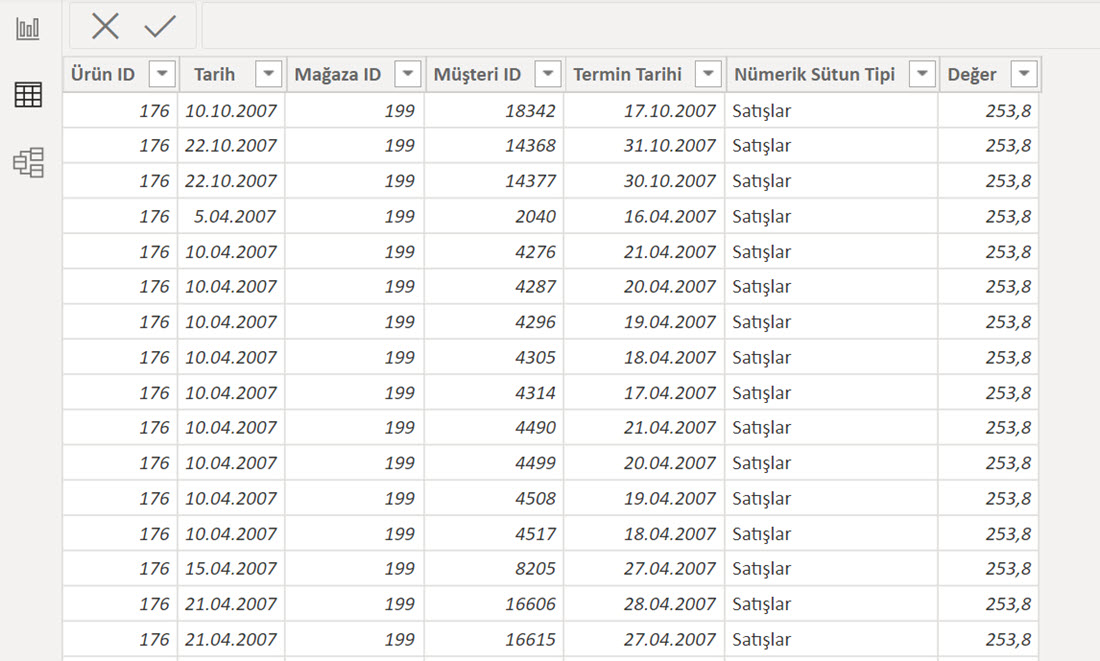
Artık her bir nümerik tip için ayrı sütunlar yok, hepsi tek bir sütunda (Değer) ama her bir satırın hangi nümerik tipe ait olduğunu da biliyoruz!
Avantajları Neler (Olabilir) ?
Mevcut durumda, sütunları rapor sayfalarına slicer olarak ekleyebiliyoruz ama metrikleri ekleyemiyoruz! (Bu durumu geçen sene çıkan harika özellik fields parameters ile çözmek mümkün gerçi)
+ Metrik değerlerini -slicer haricinde- görsellere veya sayfalara bir filtre olarak veremiyoruz. Ama sütun değerlerini çok basit bir şekilde fitre olarak her yerde kullanabiliriz.
+ Metrikleri satırda/sütunda eksenlerde istediğimiz gibi kullanmak bazen zor, görselin ne olduğuna göre değişir, ama sütun değerlerini rahatlıkla kullanırız.
Aşağıdaki gibi bir görseli bu yöntemi kullandığımızda hazırlamak çok kolay!
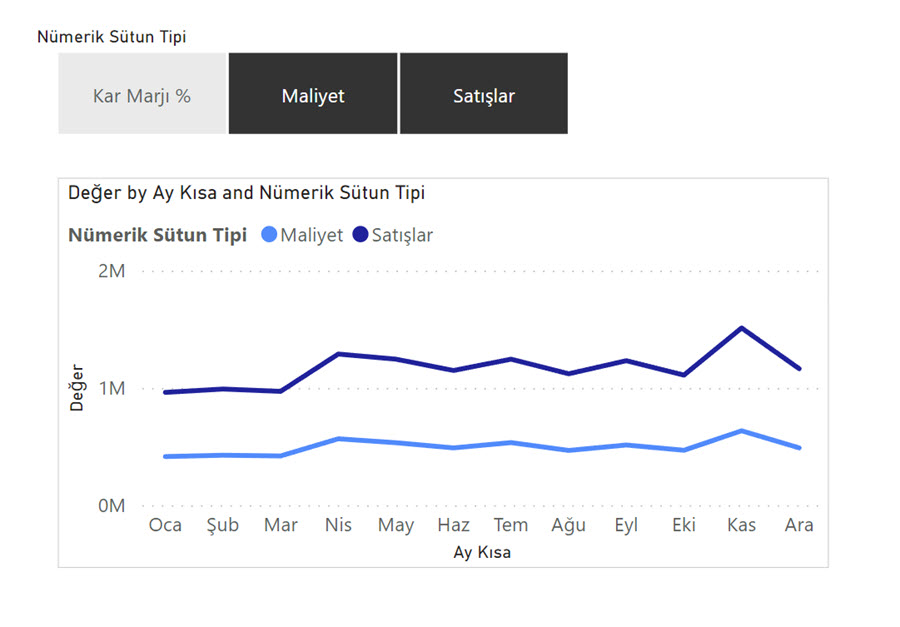
Her bir nümerik tip ilk fact tablosundaki gibi ayrı ayrı sütunlarda olsaydı, aynı görüntüyü elde etmek -görselin ne olduğuna göre değişmekle birlikte- bazen mümkün olmayabilir! Yukarıdaki line chart’ı birebir yapabiliriz, ama -misal- matris için aynı şeyi söylemek zor!
Bir başka avantajı RLS, yani row level security kulanımında. RLS’de yaptığımız iş aslında sütun değerleri üzerinden modeli filtreleyerek her filtre grubu (rol) üzerinden kullanıcılara yetki vermek. Dolayısıyla bu yöntemde şu kullanıcılar maliyeti görsün/görmesin demek çok kolay. Ama metriklerle aynı işi yapmak o kadar kolay olmayabilir.
Yazmamız gereken metrik sayısı, bu yöntemi kullandığımızda -kapsamın ihtiyacına göre- daha az olabilir.
Dezavantajları Neler (Olabilir) ?
Başlıklara “olabilir” diyorum çünkü bazı +- durumlar tamamen verinin durumuyla ilgili. Misal bu örnekteki sütunların format görünümleri aynı değil! Satışlar “currency” iken, maliyet decimal, kar marjı yüzde %.
Ayrı ayrı sütunlar olduğunda her bir sütunun formatını seçmek çok kolay. Her şey aynı sütunda olduğunda ise formatları ayrı ayrı belirlemek -mevcut durumda- ancak calculations group kullanıp format string’lerle uğraşarak yapabileceğimiz bir şey.
Gene verinin durumuna bağlı olarak dosya büyüklüğü artabilir. Sütun sayısını azalttık belki ama örnekte olduğu gibi farklı sütun tiplerini birleştirdiğimizden kardinaliteyi arttırmış olduk. Kardinalite hem model büyüklüğünü hem de yazdığımız metriklerin performansını tetikleyen en önemli etkenlerden biri. Ne kadar düşük kardinalite, o kadar iyi!
DAX Studio ile modele baktığımızda bunu anlamak kolay: Nümerik değerler ayrı ayrı sütunlardayken 19K olan kardinalite, sütunları birleştirince 57K olmuş!
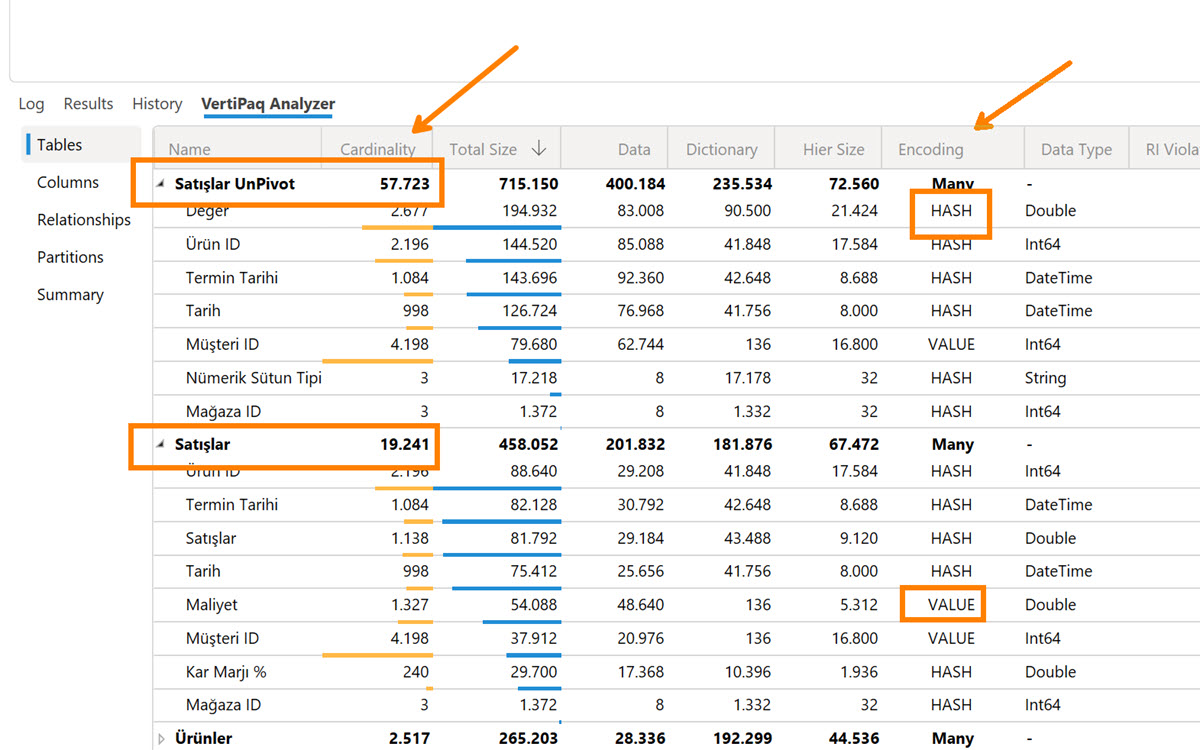
İkinci bir durum encoding (sıkıştırma diyelim basitçe) yöntemiyle ilgili. VALUE encoding ile sıkıştırılan sütunlar genelde dosya büyüklüğünü olumlu anlamda tetikler, HASH ise -genellikle- tam tersi. Misal integer tipindeki sütunlar VALUE encoding ile sıkıştırılırken, text/string sütunlar HASH ile sıkıştırılıyor. Dolayısıyla dosya büyüklüğü bu sebeple de bir miktar artabilir. (Bu encoding farkı dosya büyüklüğünü tetikleyen bir durum, performansa +- bir katkısı pek yok. GUID tarzı anahtar sütunlarınız varsa integer yapacağım diye çok uğraşmayın.
Yazmamız gereken metrik sayısı azalabilir demiştim kapsamın ihtiyacına göre ama diğer taraftan kompleksliği artabilir! Sütunlar ayrıyken basit SUM/AVERAGE gibi fonksiyonlar özellikle transactional veri ile çalışıyorsak işimizi görür. Her şeyi aynı sütuna aldığımızda biraz daha kompleks bir formül yazmamız gerekecektir.
Satışlar = SUM( 'Satışlar'[Satışlar] )
Satışlar UnPivot =
CALCULATE(
SUM( 'Satışlar UnPivot'[Değer] ) ,
'Satışlar UnPivot'[Nümerik Sütun Tipi] = "Satışlar"
)
Daha kompleks formül demek -her zaman değil ama- potansiyel olarak daha yavaş çalışmaya meyilli formül demek! Yukarıdaki örneklere göre milyar satırınız yoksa aradaki farkı hissetmezsiniz bile. Ama developer profiline sahipseniz bu tür modelleme teknikleri için ekstra bazı şeyleri bilmekte fayda var!
Hangisini Ne Zaman Tercih Edelim?
“It depends” : ) Yani duruma bağlı. Eğer nümerik sütunların mantıkları/veri tipleri birbirinden farklıysa, ayrı ayrı sütunlarla çalışmayı tercih ediyorum. Kardinaliteyi yüksek tutmamak için, formatlarla uğraşmamak için, + daha basit metrikler yazmak için.
Ama sütunların mantığı benzerse hepsini tek bir sütunda birleştirmeyi tercih ediyorum! Misal bir bütçe modeli yapıyorsunuz, bir tarafta gerçekleşen var, diğer tarafta bütçe, hatta bütçenin de versiyonları var! Bu durumda hem gerçekleşen, hem de bütçe verisini tek bir fact tablosu oluşturarak çözmeyi -genelde- tercih ediyorum. -Bana göre- daha kolay, daha yönetilebilir, daha esnek. Ben farklı sütunlarla yapıyorum diyene de itiraz etmem ama!
…
Star şemaya birebir bağlı kalacaksak -ki kalmalıyız genel olarak- , bu örnek modele bir tablo daha eklemem lazım aslında! Her bir nümerik sütün tipini içeren bir master tablo oluşturup, fact tablosuyla ilişkilendirmeliydim. Pratiğe -bu örneğe göre- pek katkısı olmazdı ama teoriye daha uygun bir model olurdu. Ne diyelim, dediğimi yapın, yaptığımı yapmayın!