Power BI ‘da performansı iki ana bölüme ayırmak mümkün: İlki rapor performansı, ikincisi de modelin güncelleme ya da jargondaki adıyda dataset refresh performansı. Rapor performansı daha çok modelinizi nasıl kurduğunuz ve metriklerinizi nasıl yazdığınızla ilgili. Artı, Direct Query ile kullanıyorsanız buna ek olarak veri kaynağının konfigürasyonu ve üzerinde çalıştığı donanım da önemli. Refresh çok uzun sürüyorsa bu daha çok veri kaynakları ve yaptığımız transformasyonlarla ilgili.
Rapor performansına kısaca değinip hızlı güncelleme için dikkat edilmesi gereken detaylara gireceğim. Öncelikle star şemadan, -hadi bazen onu da kullanalım- snowflake şemadan şaşmayın! DAX ‘la ilgili bazen fonksiyon spesifik çok ince detaylar var ama en önemli tavsiyem metriklerinizi yazarken değişkenleri kullanmanız. İkincisi de iterator fonksiyonları bilinçli kullanmak üzerine. Nerede ne zaman hangi durum için dediğini bulamadım ama DAX kompetanlarından Marco Russo sanırım bir yerde SUM(..) fonksiyonunun internal açılımı SUMX(..) demiş, bu da aggregator ve iterator fonksiyonları performans açısından aynı kefeye koymak olarak algılanmış! Basit formüllerde hemen hemen hiçbir şey farketmez, bu doğrudur. Ama bir veya birden fazla tablo üzerinde loop çevirdiğiniz ve iterasyona soktuğunuz formüller hemen her zaman için yavaş çalışmaya adaydır!
Yazı İçeriği
…
Dataset refresh’inin birden fazla boyutu var. Aşağıdaki önerilerin bazıları sadece “Import” modunda çalışıyorsanız geçerli.
Gateway Makinasının Durumu
Eğer modelinizde on-prem (yani lokal) veri kaynakları kullandıysanız modelin güncellenmesi için bir gateway kurmak şart. Modelinizde tamamı Internet üzerinden erişilebilir veri kaynakları kullandıysanız gateway kurmanıza gerek yok.
Microsoft, gateway’i kurduğunuz makina için minimum 8 core – 8 GB RAM ve stabil/hızlı Internet önerisinde bulunmuş ama bana sorarsanız minimum 16 GB RAM lazım. 8 GB RAM ile Windows’u açtığınızda 50% ‘si doluyor zaten! Refresh saatinde ilgili makinanın utilizasyonuna bakarak donanımın yetip yetmediğine karar verebilirsiniz.
Refresh ettiğiniz birden fazla modeliniz varsa bunların refresh saatleri de önemli olabilir! Aynı anda refresh etmeye çalıştığınız birden fazla dataset’in gateway’i daha fazla yoracağı açık. Güncelleme sürelerine göre dataset’leri sıralı refresh etmenizi öneririm.
Çok sayıda model/veri kaynağınız varsa birden fazla gateway makinası ile bir gateway cluster ‘da kurabilirsiniz.
Gateway makinanın modelde kullandığınız veri kaynaklarını rahat görmesi lazım dememe gerek yok sanırım!
Hangi Veri Kaynaklarını Tercih Edelim?
Kullandığımız verileri farklı formatlardan, kaynaklardan okumak mümkün. ODATA’dan tutun Sharepoint ‘teki bir listeye kadar hepsi olabilir. Veri kaynaklarının bazıları -yapıları gereği- yavaş, bazıları hızlı! Yavaş bir veri kaynağından hızlı veri çekemezsiniz!
Transactional verilerinizi “flat file” tabir edilen csv, txt, xls, xlsx gibi dosyalardan okuyorsanız önerim şu: Excel formatını, yani xls – xlsx’i transactional veriyi çekmek için kullanmayın kesinlikle! Bunun yerine csv veya parquet formatını tercih edin. Parquet formatı büyük transactional veriler için csv’ye göre genelde daha avantajlıdır. Flat file kullanmak zorundaysanız bu iki formatı kullanın.
Genelde çok fazla satır/sütun içermeyen master tabloları Excel’den okumak ise tercihinize kalmış! Ama master tablolarınız büyükse bunun için de yukarıdaki formatları kullanmanızı öneririm.
Mümkünse her zaman için incremental refresh ‘i destekleyen veri kaynaklarını kullanmak lazım. MS SQL ve çoğu -nizami- ilişkisel veri tabanları incremental refresh’i destekler ama flat file türündeki veri kaynaklarını incremental refresh için kullanamazsınız. (Bazı workaround’lar varsa da bunlar tam olarak MS’in desteklediği çözümler değil.)
Sıklıkla karşıma çıkan bir dizin altından okuyup birleştirdiğiniz Excel/csv dosyalarınız varsa bunları yapabiliyorsanız SQL’e taşımak refresh süresini fazlasıyla kısaltacaktır.
MS harici bazı veri kaynaklarına gelince, Oracle, SAP HANA gibi uygulamalar connector konfigürasyonunu doğru yaptığınız sürece gayet iyi. Teknik bilgim dışında oldukları için çok kesin yorum yapmak istemem ama bir POC esnasında aşağı yukarı 500 milyon satır/15 sütunluk bir fact tablosunu 24 saatte Teradata’dan çekemedik! Aynı veriyi SQL ‘den çekiyor olsaydık 1 saatte biterdi muhtemelen. Benzer şekilde SAP BW ile bugüne kadar olan tecrübem de son derece kötü! Dediğim gibi teknik bilgim dışında olduğu için kesin yorum yapamam, sadece tecrübemi anlatmak istedim.
Hangi Veri ve Veri Tiplerini Kullanalım?
En basit ve en etkili pratik: Sadece ve sadece modelde / görsellerde size lazım olan sütunları alın. Bu basit kurala nedense uyulmadığını görüyorum genelde, hiçbir görselde hiçbir metrikte kullanılmayan sütunları modelden çıkartmak yapacağınız ilk iş olmalı. Bunları bulmak için PowerBI Helper gibi araçları kullanabilirsiniz.
Power BI ‘ın tabular motorunun satır sayısıyla ilgili -milyarlarca satırınız yoksa- fazla bir derdi yok. Ama genede olabildiğince az satırla çalışmak iyi bir pratik. Geçen 5 yıla ait veriyle çalışmak yerine 3 yıl yetiyorsa bununla çalışın.
Veri tipleriyle ilgili bir problem yok ama Power Query ‘de mümkün olduğunca az çevrim (conversion) yapmalısınız. Veri kaynağında “double” formatında duran bir sütunu PQ ile currency formatına çevirmek yerine kaynakta da currency formatında tutun. Ne kadar az çevrim o kadar hızlı refresh!
GUID tarzı değer içeren sütunları, eğer SQL gibi bir veri kaynağıyla çalışıyorsanız tipini integer yapacağım diye çok uğraşmayın. DAX ve metriklerin çalışma hızı açısından -misal- bir anahtar sütun integer olmuş GUID olmuş farketmiyor. Ama okuduğunuz veri kaynağı bu tür sütun tipleriyle hızlı olmayabilir (misal flat file kaynaklar, bazı web servisleri). Eğer durumunuz buysa test yapmanızı öneririm.
Sütunlarla ilgili en önemli şey, tiplerinden ziyade içerdikleri tekil değer sayısıyla ilgili. DateTime tipi sütunları Date’e çevirmek veya Time kısmı da lazımsa Date ve Time olarak farklı sütunlara bölmek iyi bir pratiktir ama bunun asıl sebebi DateTime tipinin kötü olması değil, bu tipteki sütunların yüksek kardinaliteye (tekil değer sayısı) sahip olma ihtimalinin yüksek olmasıdır. Yüksek kardinalite refresh süresini uzattığı gibi, dosyanızın büyüklüğüne de en fazla etkiyi yapan şeydir: 12 milyar satır içeren bir Power BI dosyası, 2 satır ve 4 sütun içeren bir Power BI dosyasından daha küçük olabilir! Kardinaliteyi düşürün!
Sütunları Nerede Ekleyelim?
Zaman zaman orijinal veri kaynağında doğrudan olmayan ama veriden türetebileceğimiz sütunlara ihtiyaç duyarız, özelliklede fact tablolarında. Bu sütunları modele hangi aşamada ekleyeceğiniz refresh zamanını tetikler. Diyelim -daha basit formüller yazmak için- fact tablomuzda miktar ve fiyat sütunu var ve tutar sütunu eklemek istiyoruz, veya müşteriler tablosunda müşterinin doğum tarihi var, yaşını getirmek istiyoruz. Bunu hesaplanmış sütun olarak DAX ile veri modeli tarafında yapabiliriz, Power Query’de yapabiliriz veya veri kaynağında yapabiliriz.
İlk tercih bu tür sütunları orijinal veri kaynağında yaratmak olmalı.
Veri kaynağına doğrudan müdahele yetkiniz yoksa ikinci tercih Power Query olmalı.
Hesaplanmış sütun en son opsiyon!
Bu 100% her zaman geçerli olmayabilir (ekleyeceğiniz sütunun mantığına göre) ama PQ tarafında eklenen sütunlar, veri modeli tarafında DAX ile ekleyeceğiniz sütunlara göre -genellikle- daha hızlı çalışır. Misal SWITCH veya IF fonksiyonuyla DAX tarafında eklediğiniz bir hesaplanmış sütun varsa bunun yerine PQ’yu kullanın. Daha hızlı refresh edecektir.
Bu tür sütunların (DAX veya PQ tarafında) hesaplandığı an dataset’in refresh edildiği an. Dolayısıyla veri kaynağında yaratmak daha doğru bir tercih.
SQL ile Çalışırken Neye Dikkat Edelim?
Veri kaynağı olarak bir SQL server kullanıyorsanız, her zaman için doğrudan tablolara bağlantı yapmak yerine view’ları kullanın!
View’larınızın altındaki sorgu, milyar satırınız yoksa ve import modunda çalışıyorsanız şu basitlikte olmalı:
SELECT
Modelde lazım olan sütunları tek tek belirtin
FROM
Hangi tablodan gelecekse
WHERE
Ana filtrelerinizi belirtin, firma kodu gibi, 2020 sonrası gibi
Eğer -misal – fatura numarası lazım değilse veya transaction saat bilgisi gerekmiyorsa , GROUP BY deyip müşteri-gün bazında gruplayabilirsiniz ya da Ürünler master tablosuna LEFT JOIN deyip ürünün markasını / kategorisini de getirebilirsiniz.
Import modunda çalışıyorsanız bu basitlikte bırakın.
Ben -kişisel tercih olarak- tek bir tablo üzerinden oluşturulmuş basit SELECT FROM WHERE view’larını kullanmayı daha kullanışlı ve yönetilebilir buluyorum. Join yapacaksam, filtre koyacaksam bunu PQ ile yapmayı daha pratik buluyorum.
Çünkü eğer query folding‘e de dikkat ediyorsanız, bu join’ler filtreler ya da Group By’lar view sorgusunda olmuş ya da PQ’da olmuş performans açısından farketmiyor. Sonuçta query folding devredeyse SQL’den veri her halükarda T-SQL ile isteniyor.
Query Folding’i desteklemeyen transformasyonlar varsa (ilk harfleri büyük yap gibi) bunu SQL tarafında yapmayı tercih edebilirim, ama destekleyen tüm transformasyonları PQ ile yönetmek -bana göre- daha pratik.
View’lar materyalize edilmemiş sorgulardır. Yani içinde veri tutmazlar, siz çağırdığınızda -refresh esnasında- çalışırlar ve istediğiniz veriyi döndürürler. Eğer yazdığınız sorgu, F5’e bastınız yarım saat sürüyorsa bunun Power BI ile hiç ilgisi yoktur. Yazdığınız sorgunun kalitesi / tipi veya üzerinde çalıştığı donanımla ilgisi vardır. Bu tür sorguları materyalize etmek bu süreyi elimine etmenizi sağlar, ama veritabanınızda da yer tutar!
Snapshot – transactional veri konusunu iyi ayarlayın. SQL tarafında veri kaynağı olarak gereğinden fazla hesap/kitap hem elinizi kolunuzu bağlayabilir hem de refresh süresini uzatır (F5 süresinden dolayı).
Power BI Türkiye meetup grubuyla yaptığımız SQL for the Power BI Developer videosunu da izlemenizi öneririm.
DataFlow ‘ları Kullanın !
Dataflow’lar Power BI ekosisteminin temel yapı taşlarından biri. Eğer hali hazırda düzgün tasarlanmış bir veri ambarınız yoksa dataflow’ları kullanmanızı öneririm. Özellikle aynı/benzer verileri birden fazla veri modelinde kullanıyorsanız, dataflow size veriyi sadece 1 kez refresh ederek birden fazla modelde kullanma imkanı sağlar.
Dataflow’lar ile bir staging katmanı oluşturabilirsiniz, staging dataflow’ları nihai modelde kullanacağınız başka bir dataflow’a bağlayabilirsiniz. Burada da bir ipucu vereyim: Pro lisansıyla dataflow oluşturup kullanabilirsiniz. Ama teknik olarak Premium ya da Premium Per User lisansıyla kullanabileceğiniz teknik kabiliyet daha fazla. Tek bir PPU lisansı ile (Pro lisansa ek olarak 10 USD maliyeti var sadece) Azure’da satın alacağınız bir Azure Data Lake Storage‘ı merkezi bir veri ambarı olarak kullanabilirsiniz. Tek bir PPU lisansıyla ADLS üzerinde dataflow oluşturun, bunu tenant’ınıza ya da workspace’inize bağlayın, Pro lisansıyla model geliştirin! ADLS Gen 2 fiyatları çok makul.
PowerBI Desktop Ayarları
Eğer Pro lisansınız varsa, PowerBI.com servisinin gateway üzerinden refresh yaparken timeout süresi 2 saat. 2 saat içinde refresh etti etti, edemedi hata veriyor! Eğer Premium lisansınız varsa bu süre 5 saat!

Bu süreleri değiştirmenin herhangi bir yöntemi yok!
Bulut servisinin refresh etme süresini Power BI Desktop’tan refresh ettiğiniz süreyle bir tutmamak gerek. Model geliştirirken desktop’tan yaptığınız refresh arada bir gateway olmaksızın geliyor. Arada birşey yok! Dolayısıyla veri kaynaklarıyla aranızda bir bağlantı sorunu yoksa daha hızlı olacaktır.
Ama Power BI Desktop’ta yapacağınız bazı ayarlarla servisin refresh etme süresinin kısalmasına yardımcı olabilirsiniz.
Veri güvenliği ile ilgili ne yaptığınızdan eminseniz Data Privacy opsiyonlarını devreden çıkartabilirsiniz.
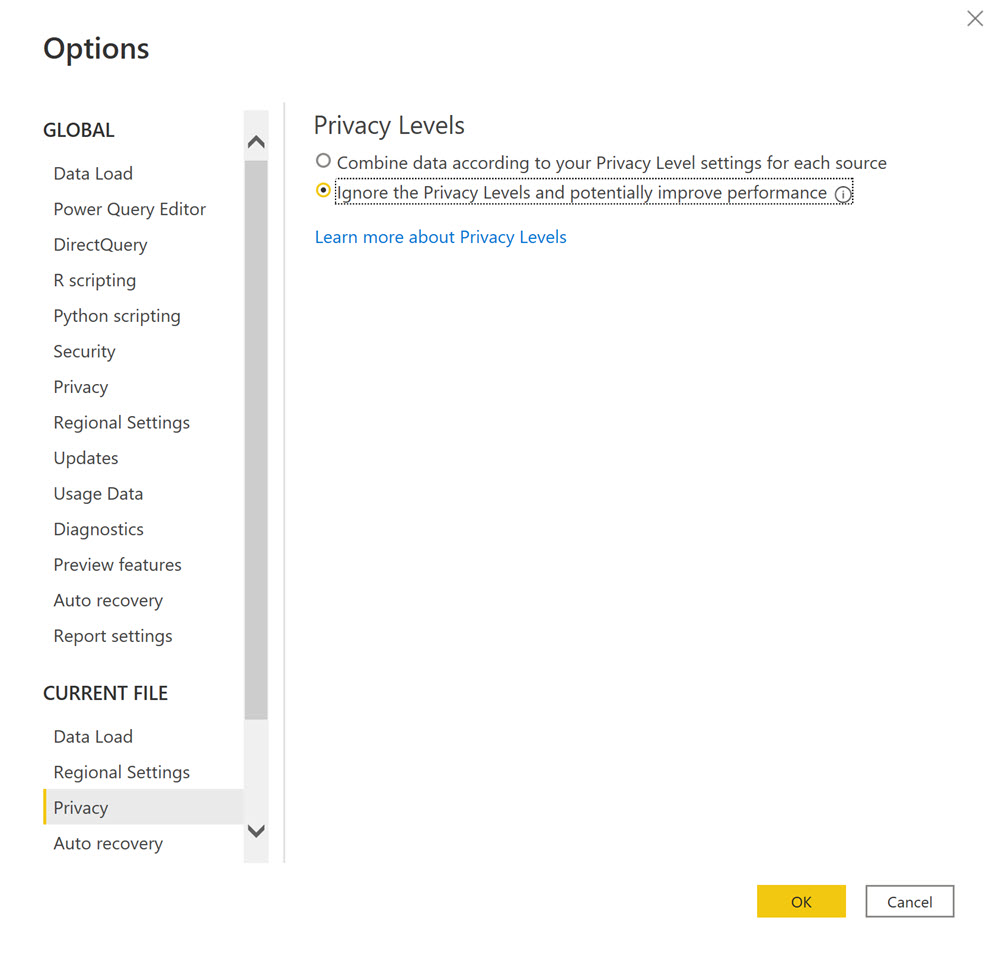
Modelinizde her zaman için nizami bir tarih tablosu olsun ve Auto Date/Time’ı kapatın.
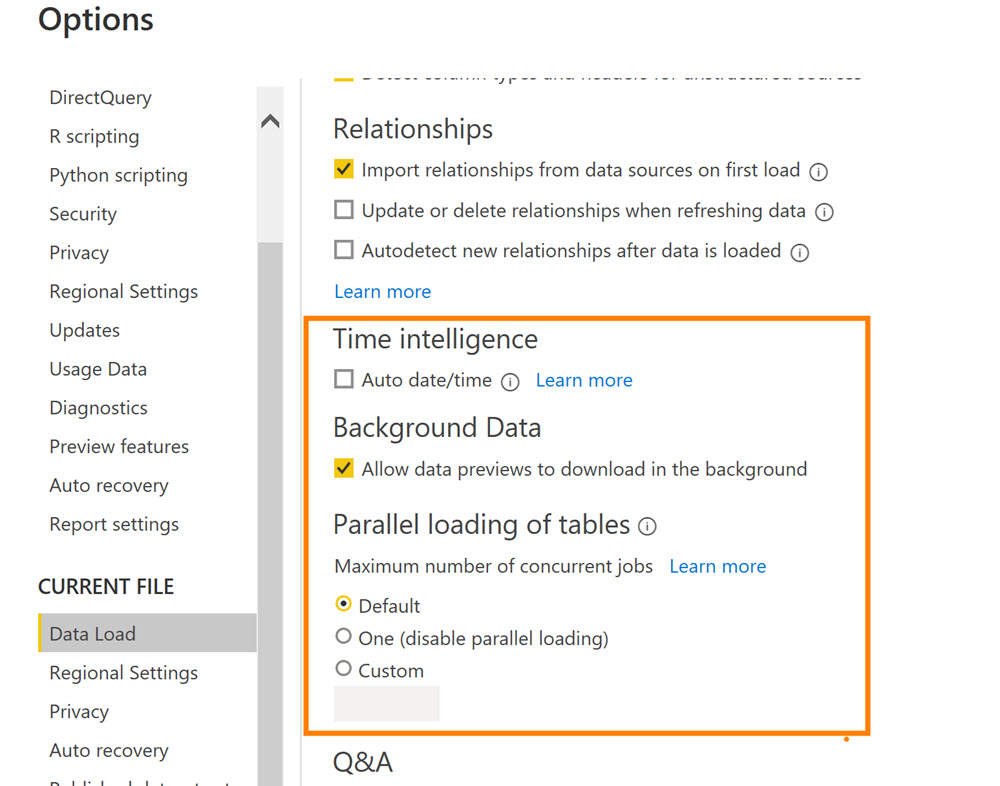
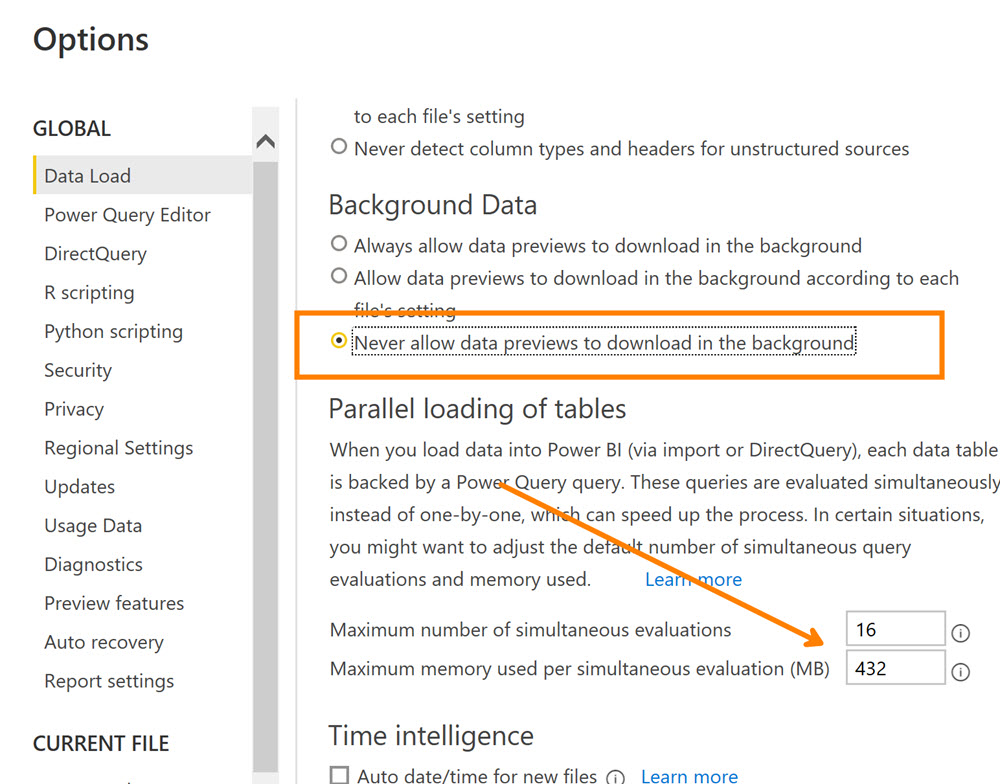
Ayarlardaki “Allow data preview …” opsiyonunu kapatın (tikini kaldırın).
“Parallel loading of tables ..” opsiyonlarıyla da denemeler yapmanızı öneririm. ( Hem Current File hem de Global opsiyonlardan) Kullanılan hafıza miktarını arttırmak, anlık maksimum bağlantı sayısını azaltmak/arttırmak işe yarayabilir.
Refresh Diagnostics
Her bir refresh ne kadar sürüyor bunun bir tarihçesi ilgili dataset’in refresh ayarlarında var.
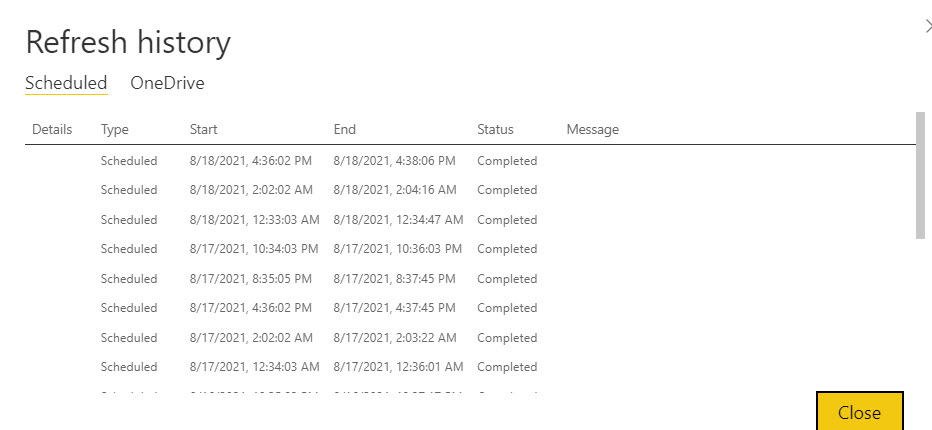
Ama bu sürelerin ne kadarını veriyi çekerken, ne kadarını veriyi transforme ederken, ne kadarını kaydetmek üzere process ederken harcadık gibi detaylar yok.
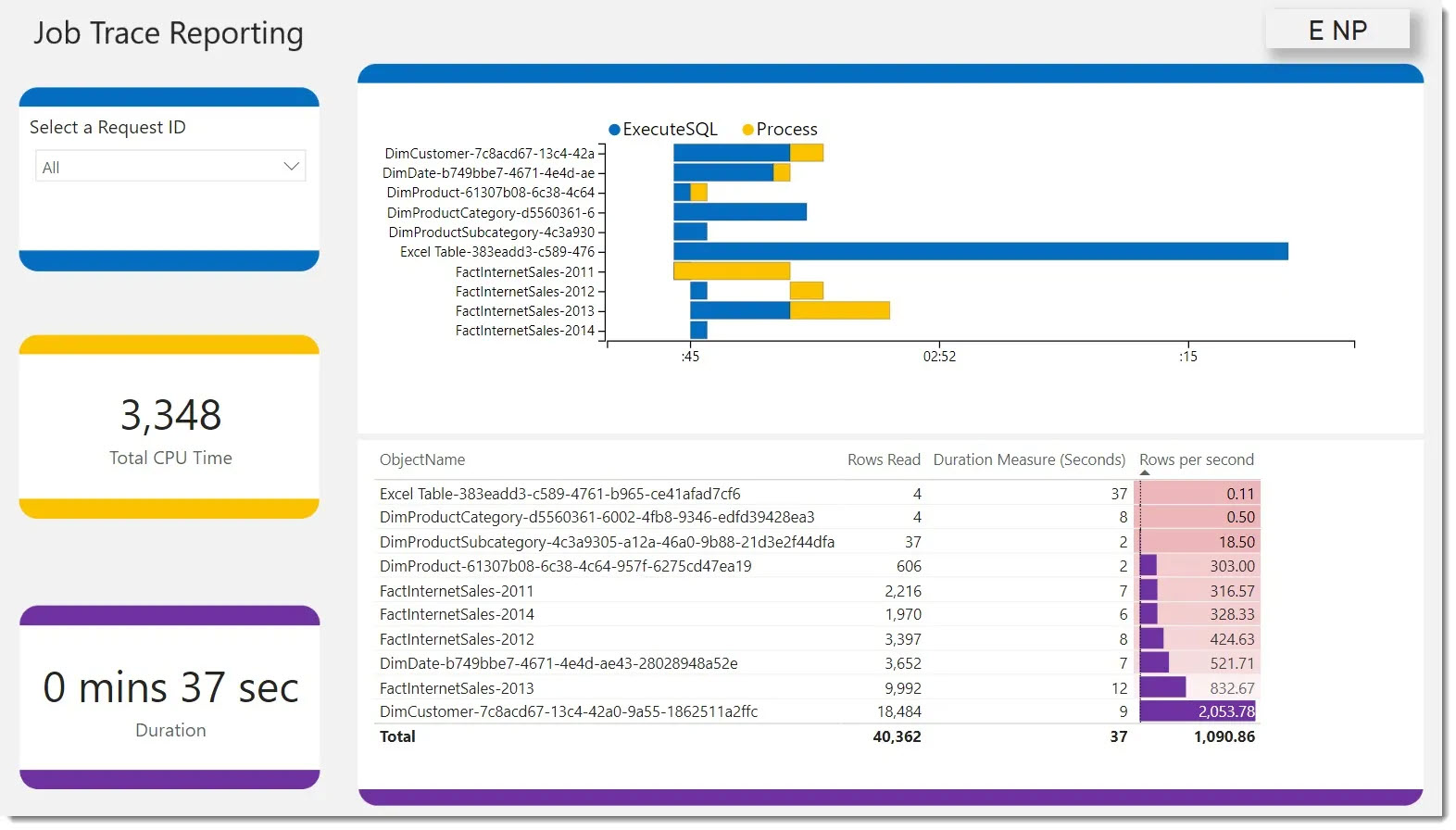
Bunun için iki tane araç var kullanabileceğimiz: İlki Power Query’deki Query Diagnostics, diğeri de Power BI CAT takımından Phil Seamark’ın hazırladığı template’i kullanmak! İkincisi size nereye bakmanız gerektiği konusunda daha fazla ipucu veriyor, çünkü hangi tablo için nerede ne kadar süre harcadığınızı görebiliyorsunuz.
Veri Transformasyonlarını Nerede Yapalım?
Power Query Power BI’ın ETL aracı, amacı zaten “power user”‘ların işini kolaylaştırmak, o yüzden transformasyon yapmayın demek yanlış olur. Ama SQL ile çalışırken query folding’i sonuna kadar kullanın. Desteklenen stepleri en başlarda yapıp desteklenmeyen stepleri en sonlara bırakmak yeterli.
Olabildiğince az step elbette refresh süresini azaltır. Eğer bir veri ambarı dolduruyorsanız veri transformasyonlarını veri kaynağına en yakın noktada yapmak da iyi bir pratik.
Gene Power BI CAT takımından Mathew Roche’un bu yazısına bir göz atın.

Özet ve Önerilerin Öncelik Sırası
Hızlı ve incremental refresh’i destekleyen veri kaynağı, sadece lazım olan sütunlarla çalışma, minimum sayıda transformasyon, query folding’ten sonuna kadar yararlanma, flat dosya ise csv/parquet formatı, gereksiz hesaplanmış sütun oluşturmamak eğer bir top 10 listesi yapsaydım ilk sıralarda olurdu.
Kısa süren refresh’ler dilerim!