Power Query ile bir SQL sunucuya bağlanıp veri çekmek için temelde iki farklı yöntem kullanabiliriz:
- Sunucu ve veritabanı adını yazıp OK diyerek ilgili veritabanındaki tabloları seçebiliriz.
- “SQL Statement” bölümüne istediğimiz veriyi çekecek SQL cümlesini yazabiliriz.
İlk yöntemi kullanarak “Satışlar” tablosunu seçiyorum.
Belge para birimi “TL” ve satış tutarı 100’den büyük olan satırları almak için filtre stepleri oluşturuyorum. Gereksiz olan bazı sütunları da siliyorum.
Buraya kadar aslında, bir veri tabanındaki bir tabloya bağlanıp, belli şartları sağlayan satırları (TL ve tutarı 100’den yüksek olanlar) ve lazım olan sütunları seçtik.
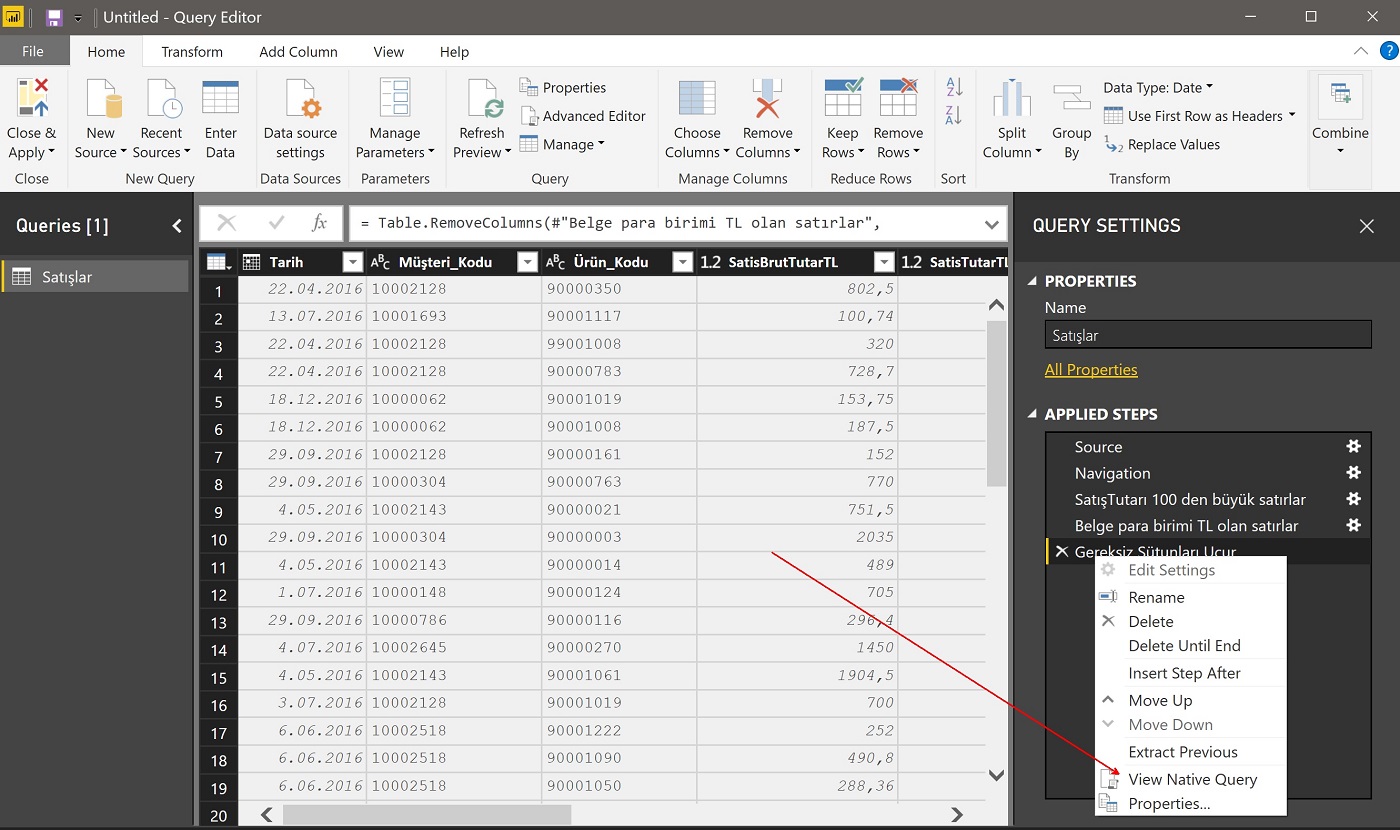
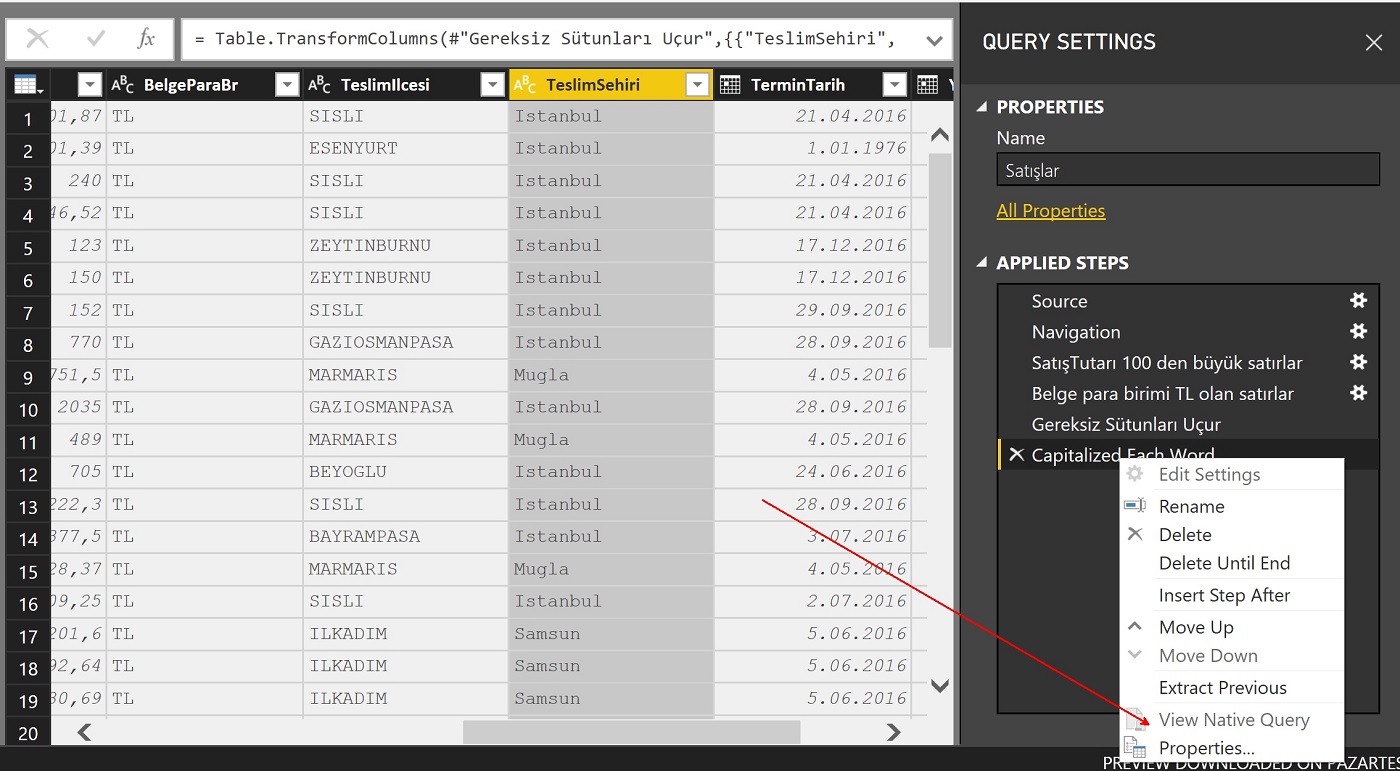
En son step’i sağ tıklayıp çıkan menüden “View Native Query”‘yi seçiyorum.

Buraya kadar yaptığımız tüm stepler, doğal bir SQL SELECT cümlesine dönüştürülmüş! Yani Power Query, bu steplerin sonucunda gelmesi gereken veriyi, SQL sunucudan “kendi dilinde” istemiş.
Tablodaki sütunlardan “Teslim Şehri” değerlerinin ilk harflerini büyük yapacak şekilde bir step daha oluşturuyorum.
Bu son aşamayı sağ tıkladığımızda karşımıza çıkan menüde “View Native Query” opsiyonu seçilebilir durumda değil. Bir başka deyişle, Power Query istediği verinin doğal -native- sorgusunu bu aşamada oluşturamadı.
Query folding; veri çekme ve veri dönüştürme işlemlerinin istemci (client) üzerinde değil, doğrudan veri kaynağı olan sunucu (server) üzerinde, sunucunun doğal dilinde yapılmasını sağlayan bir özelliktir.
Bu neden önemli? En basitinden örneklemek gerekirse, yukarıdaki “Satışlar” tablosu 100 milyon satırsa, “query folding” ile sadece bize lazım olan TL para birimli ve tutarı 100’den büyük olan satırlar daha istemciye gelmeden sunucu üzerinde kendi dilinde filtrelenir. Dolayısıyla gereksiz bir veri trafiği yaratmamış oluruz, -genellikle- daha güçlü olan sunucunun kaynaklarını kullanmış oluruz, veri kaynağının kendi “native” diliyle sorgu oluştuğundan hızlı çalışır.
Query folding’in çalışabilmesi için bazı şartlar var:
- Veri kaynağının bu özelliği destekliyor olması lazım. SQL, Oracle, Odata gibi veri kaynakları bu özelliği destekler. Csv, xls dosyaları gibi -flat file- veri kaynakları bu özelliği desteklemez.
- Veriyi dönüştürdüğümüz aşamanın da uygun olması gerekir, her transformasyon bunu desteklemiyor. Yukarıdaki örnekte, filtre ve sütun silmelerin desteklendiğini ama “Capitalize Each Word” transformasyonunun desteklenmediğini gördük.
- Yazının başlangıcında gösterdiğim “SQL Statement” bölümüne kendi SELECT sorgumuzu yazsaydık (Select * from Satışlar -gibi-) query folding hiç desteklenmeyecekti.
Query folding, genel olarak veri çekme-dönüştürme hızını pozitif anlamda etkilediğinden bu özellikten maksimum faydalanmak gerekir.
Yukarıdaki örnekte, “Capitalize Each Word” transformasyonunu ilk stepte kullansaydık, query folding daha ilk stepte geçersiz olacaktı. Dolayısıyla sonraki steplerde -örneğin- TL olan satırları filtrelemek için tüm satış satırlarını çekmek ve filtreyi istemci üzerinde yapmak zorunda kalacaktık. Desteklenmeyen bu transformasyonu sona koymak, query folding’in en azından desteklenen stepler boyunca çalışabilmesini sağladı.
Yazıyı toparlamak gerekirse:
- Query folding, sorgunun veri kaynağının kendi dilinde ve sunucu tarafında çalışmasını sağladığından performansı arttırır.
- CSV dosyaları gibi bu özelliği desteklemeyen veri kaynaklarını SQL tablolarına taşımak performansı arttırır.
- Native Query’yi destekleyen, filtreleme, sütun silme, basit transformasyonlar, group by, merge, join’ler, nümerik hesaplamaları önce yapıp, desteklemeyen transformasyonları sonlara bırakmak bu yetenekten mümkün mertebe faydalanmamızı sağlar.
- Veritabanına bağlanmak için SQL Statement bölümüne SQL cümlesi yazmak, Table.Buffer, List.Buffer gibi M fonksiyonları kullanmak, query folding’i desteklemez.
Eğer Power BI dosyanız, “Refresh” dediğinizde güncellemesi çok uzun sürüyor (>10 dakika) ve istemci makineyi uzun süre 100% utilize ediyorsa yukarıdaki önerilere göre değişiklikler yapmanız faydalı olabilir.