DAX’taki temel kavramlardan ikisine giriş yapalım: Aggregator’lar ve iterator’lar.
Daha önce bahsettiğim gibi DAX’ta hücre kavramı yoktur, tablo ve sütun kavramı vardır, tablolar satır ve sütunlardan oluşur. Tablo, tek bir satırdan ve tek bir sütundan oluşuyor olabilir; bu da bir tablodur.
Aggregator fonksiyonlar (SUM, AVERAGE, MIN, MAX …), sütun bazlı çalışırlar, sizden tek bir parametre isterler: Üzerinde çalışacakları sütunun adı. Gördükleri, aggregate ettikleri yani topladıkları, ortalama aldıkları vs, tek şey sütundur. Satır görmezler.
Aggregator’lar, sadece tek bir sütun üzerinde çalışır, birden fazla sütun üzerinde çalışmazlar.
Satışlar := SUM ( 'Satışlar'[Tutar] )
diyebiliriz. Fakat
Satışlar := SUM ( 'Satışlar'[Miktar] * 'Satışlar'[Fiyat] )
diyemeyiz. Çünkü yukarıda da söylediğim gibi, aggregator’lar satır diye bir şey görmezler. Tek ve yegane gördükleri şey sütundur.
Aggregator’lar sadece nümerik sütunlar üzerinde çalışır, date, text ve diğer tipteki sütunlarla çalışmaz.
Yukarıda satışlar tablosundaki “Tutar” alanını topladığımız formül bir metrik, ölçü. ( = işaretinden önce : koyarak yazdığım her şeyin bir metrik olduğunu unutmayın lütfen, : yoksa -eğer yanlışlıkla unutmadıysam- her zaman bir hesaplanmış sütundur.)
Aynı formülü bir hesaplanmış sütun (calculated column) olarak Satışlar tablosuna eklesek ne olur?
Hesaplanmış Sütun SUM = SUM ('Satışlar'[Tutar] )
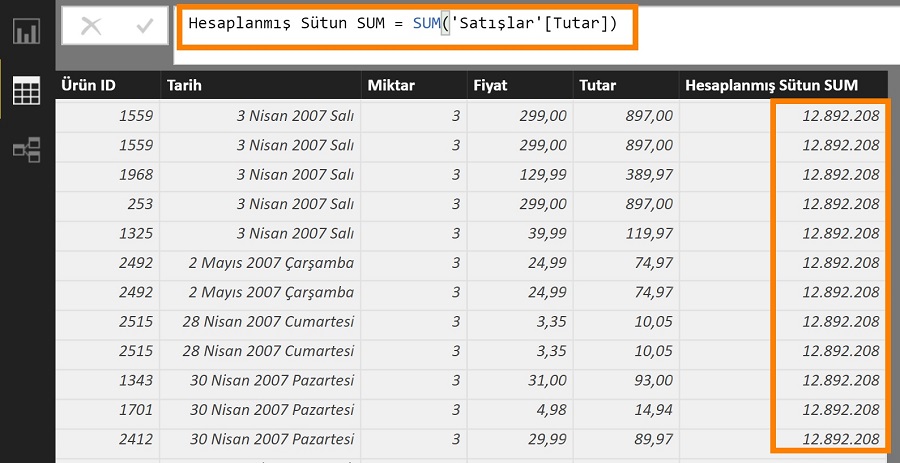
Her satırda aynı değeri, tüm satışları gösteriyor ! Açıklama aynı: aggregator’lar satır görmezler, sütun görürler. Gördüğü de “Tutar” sütunundaki tüm değerler olduğu için her satır için tüm tutarların toplamını getiriyor.
Sadece nümerik sütunlarla da çalışsa, aynı anda sadece tek sütun üzerinde de çalışsa, tek bir formül yazarak satışların bir çok farklı versiyonunu elde edebiliriz. (Bakınız Veri Modeline Giriş )
SUMX ise bir iterator’dur. İterator’lar her zaman iki parametre ister:
SUMX( 'İterate Edilecek Tablo' ;
İlgili tablonun her bir satırı için hesaplanacak deyim
)
İterate edilecek tablo, doğrudan bir tablonun adı olabilir, ya da geriye tablo döndüren bir tablo fonksiyonu da olabilir, yeter ki elimizde iterate edeceğimiz, yani satır satır üzerinde çalışacağımız bir tablo olsun.
İterator’lar, ilk parametrede verilen tabloda gördüğü satırları önüne alır, ilk satırdan başlamak üzere her bir satır için belirtilen işlemi tek tek yapar, bulduğu sonucu kenara yazar (fiktif bir sütun oluşturur gibi düşünün), tabloda gördüğü tüm satırları bitirdiğinde bulduğu değerleri aggregate eder. ( Toplar, ortalamasını alır, vs.)
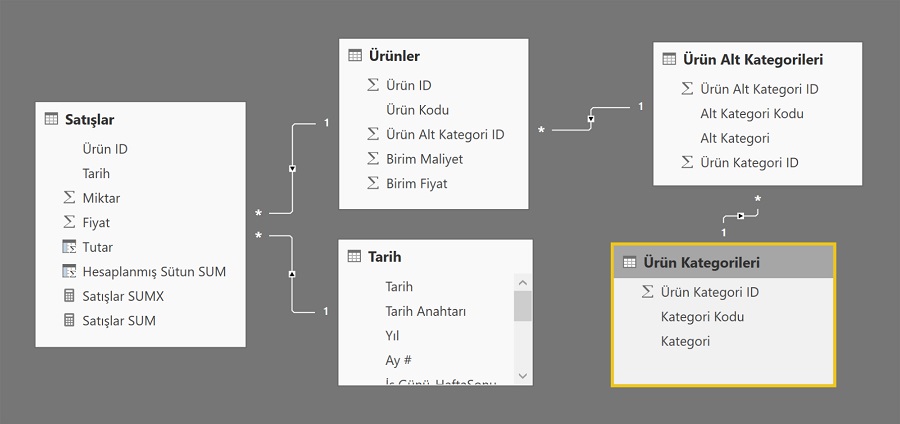
Örnek modelde, Satışlar tablosunda Miktar, Fiyat ve Tutar alanları var, “Tutar” sütunu, Fiyat ve Miktar sütunlarının çarpılmasıyla edilmiş bir hesaplanmış sütun. Tablolar arası ilişki de aşağıdaki gibi:
Satışları bu sefer SUMX ile bulalım:
Satışlar SUMX :=
SUMX ('Satışlar'; 'Satışlar'[Miktar] * 'Satışlar'[Fiyat] )
Tabular engine’nin bu komutu çalıştırırken kurduğu cümleler şuna benzer:
- Üzerinde çalışacağım tabloyu buldum: ‘Satışlar’
- Satışlar tablosunda gördüğüm tüm satırları önüme aldım,
- İlk satırdan başlamak üzere her bir satır için [Miktar] ve [Fiyat] sütunlarını çarpıp, satırın kenarına not ettim,
- Tüm satırları bitirdiğimde (iterate ettiğimde), her bir satır için bulduğum değerleri topladım.
Cümleleri bu şekilde yazıyorum, formül yazarken “DAX Man” gibi düşünmek önemli çünkü.
SUM’la ve SUMX ile yazdığımız her iki formül de aynı sonucu verir;
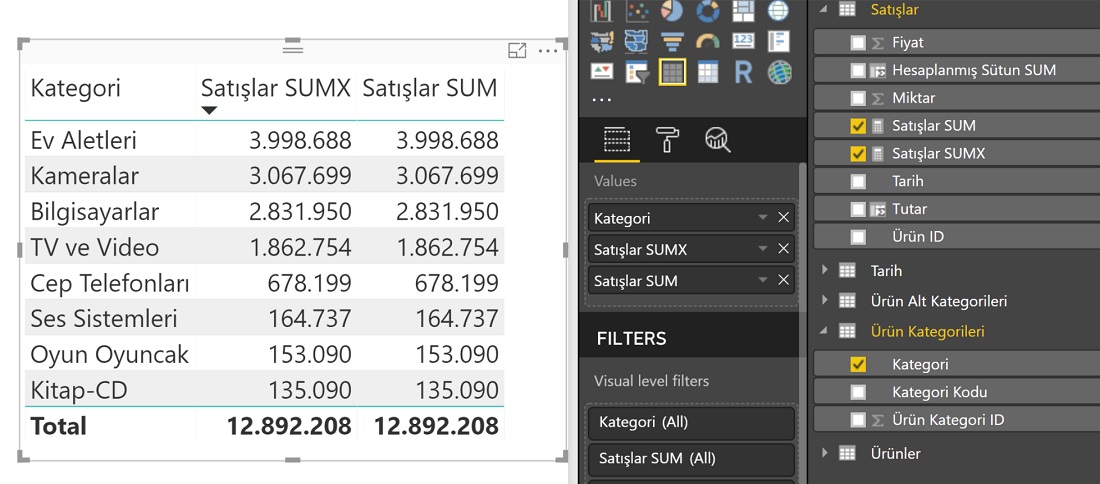
Gördüğün kelimesini ısrarla yazıyorum, çünkü her komut/fonksiyon, ister iterator olsun ister aggregator, “gördüğü” satır veya sütunlar üzerinden hesaplama yapar. Ve DAX’ta her bir görselin her bir hücresi ayrı ayrı hesaplanır.
Ev Aletleri kategorisi için bulunan değerleri “DAX Man” gibi konuşmaya çalışarak yorumlayalım:
Satışlar SUM:
- Kategoriler tablosundan “Ev Aletleri” kategori satırını aldım,
- OK yönünde hareket edebildiğim için, önce kategorisi “Ev Aletleri” olan “Alt Kategoriler”‘i buldum, sonra bu alt kategorilere ait ürünleri buldum (gene OK yönünde ilerleyebildiğim için), sonra bulduğum bu ürünlerin “Satışlar” tablosundaki satırlarını ayrı bir tabloymuş gibi ayırdım (filtreledim),
- Bu filtrelenmiş tablonun “Tutar” sütunundaki tüm değerleri topladım.
Satışlar SUMX: (ilk iki cümle aynı)
- Kategoriler tablosundan “Ev Aletleri” kategori satırını aldım,
- OK yönünde hareket edebildiğim için, önce kategorisi “Ev Aletleri” olan “Alt Kategoriler”‘i buldum, sonra bu alt kategorilere ait ürünleri buldum (gene OK yönünde ilerleyebildiğim için), sonra bulduğum bu ürünlerin “Satışlar” tablosundaki satırlarını ayrı bir tabloymuş gibi ayırdım (filtreledim),
- Bu filtrelenmiş tabloyu aldım, her bir satırı için [Miktar] ve [Fiyat] sütunlarındaki değerleri çarpıp kenara yazdım, tüm satırları bitirdikten sonra bulduğum değerleri topladım.
SUM ve SUMX üzerinden anlatıyorum ama, aggregator ve iterator fonksiyonlarının tamamı bu şekilde cümleler kurarak çalışır.
SUM’mı Kullanalım SUMX’mi? (AVERAGE’mi AVERAGEX’mi?)
Duruma göre değişir; yukarıdaki örnekte her ikisi de aynı kapıya çıkar. Fakat bazen veriye ve ihtiyaca göre değişebilir.
Şöyle bir tablomuz olduğunu varsayalım:

Eğer ziyaret başına ortalama harcama hesabı yapmak gerekiyorsa basit bir aritmetik ortalama alamayız, yanlış olur:
Ortalama Harcama Yanlış :=
AVERAGE ('Müşteri Harcama'[Ziyaret Başına Harcama] )
Ağırlıklı ortalama almamız gerekir:
Ortalama Harcama :=
DIVIDE(
SUMX ( 'Harcama';
'Harcama'[Ziyaret Başına Harcama] * 'Harcama'[Ziyaret Sayısı]
) ;
SUM ( 'Harcama'[Ziyaret Sayısı] )
)
Yeri gelmişken sonu “X” ile biten komutların hepsi iterator’dır, fakat X ile bitmese de iterator olan fonksiyonlar vardır: FILTER vs gibi.
Aşağıdaki her iki formül de her zaman aynı sonucu verir, birbirine eşittir. Fakat hesaplama yaparken DAX’ın kurduğu cümleler farklıdır, ilki sütunu doğrudan görür ve toplar, ikincisi satır bazlı hesaplama yapar, tüm satırlar bitince bulduklarını toplar.
Tutar SUM := SUM ('Satışlar'[Tutar] )
Tutar SUMX := SUMX ('Satışlar'; 'Satışlar'[Tutar] )
Benzetme yapmak gerekirse: bir lise öğrencisine “Sana günde 100 TL versem bir hafta sonra kaç paran olur?” sorusunu sorsanız direkt 700 cevabını alırsınız. Matematiği yeni öğrenen bir ilkokul öğrencisine sorarsanız parmak hesabı yapar, her bir gün için 100 TL’yi aklında tutar, 7 kez parmaklarını sayar, bulduklarını en sonunda toplar.
…
SUMX ( Tablo Adı; dedikten sonra yazacağımız deyimde kullanabileceğimiz sütunlar -normalde- ilgili tablonun sütunlarıdır.
Peki başka bir tablodaki değeri kullanmak istersek ne yapmamız gerekiyor ? Örneğin “Satışların Maliyeti”‘ni hesaplamak istediğimizi varsayalım. Her bir ürünün birim maliyeti “Ürünler” tablosunda var ve Satışlar tablosuyla Ürünler tablosu ilişkili. ( Tablolar arasındaki ilişkileri gösteren resim). Satışlar tablosundaki her bir satır için satılan miktar ile ürünün maliyetini çarpar ve bulduğumuz sonuçları toplarsak Satışların Maliyeti’ni bulabiliriz.
Aşağıdaki formülü yazdığımda ;
Satışların Maliyeti :=
SUMX ('Satışlar'; 'Satışlar'[Miktar] * 'Ürünler'[Birim Maliyet] )
Power BI hata veriyor:

Çoğu MS hata mesajı gibi oldukça uzun bir hata mesajı ama derdini ilk cümlede belirtmiş aslında:
“Ürünler tablosunda Birim Maliyet sütununun değerini bulamıyorum.”
SUMX gibi iterator fonksiyonlar -normalde- hangi tabloyu verdiyseniz o tabloyu görür sadece. Tablolar arası ilişkilerin farkında değildir. Zaten formülü daha yazarken bile [Birim Maliyet]’ın altını kırmızıyla çizdi.
İlişkinin “One” tarafındaki “Ürünler” tablosunda bulunan [Birim Maliyet] sütununun değerini bulabilmesi için aradaki ilişkinin farkına varmasını sağlamamız lazım; bunu da RELATED fonksiyonu ile yapabiliriz.
Satışların Maliyeti :=
SUMX ('Satışlar'; 'Satışlar'[Miktar] * RELATED ('Ürünler'[Birim Maliyet] ) )
RELATED fonksiyonu, arada kaç tane ilişkili tablo olursa olsun, ilişki(ler)in “one” tarafındaki tablonun sütunlarına erişmemizi sağlar.
RELATED ve ekürisi RELATEDTABLE ile ilgili ayrı bir yazı yazacağım. Her iki fonksiyon için de şimdiden şöyle bir not düşebiliriz: satır bazlı işlemlerde (yani iterator kullandığımız durumlarda) ilişkilerin “one” tarafındaki (RELATED) ya da “many” tarafındaki (RELATEDTABLE) tablolara erişmemizi sağlarlar.
…
Iterator’lar ve aggregator’lar arasındaki performans farkına değinmek gerekirse; ilk örnekte olduğu gibi aynı tablodaki sütunların çarpımı bölümü tarzındaki işlemlerde herhangi bir performans farkı görmek çok mümkün değil. Fakat yazdığınız DAX kodunun kalitesi! bunu değiştirebilir.
DAX’ta iki farklı hesaplama “engine”‘i bulunur: Storage Engine ve Formula Engine. Storage Engine her zaman daha hızlıdır, işlemciyi ve işlemcinin “cache”‘ini kullanır, multi-threaded’dir (Türkçe karşılığı varsa bilmiyorum) . Formula Engine, Storage Engine’nin tek başına işlemciyle yapamadığı hesaplamalarda devreye girer, hafızayı kullanır, daha yavaştır, single-threaded’dir ve “cache” yoktur.
** Dax Studio ile, yazdığımız formül sadece Storage Engine’ni mi kullanıyor, yoksa Formula Engine’de taşıyor mu bulmak mümkün. Yazının konusunu fazla geçmeye gerek yok şimdilik, DAX optimizasyonuna sıra geldiğinde bu konuyu da açmakta fayda var.
SUM gibi aggregator’lar her zaman Storage Engine’i kullanır. Dolayısıyla her zaman hızlıdır.
SUMX gibi iterator’larda -yazdığınız kodun ne olduğuna göre, iterate ettiğiniz tablonun satır/sütun sayısına göre- Formula Engine devreye girebilir.
Aşağıda -aslında aynı hesaplamayı yapan- üç faklı kod var: Hepsi de fiyatı 100’den büyük olan ürünlerin toplam satışlarını buluyor.
Fiyatı 100 den Büyük Ürünler :=
SUMX ( FILTER ('Satışlar'; 'Satışlar'[Fiyat] >100) ; 'Satışlar'[Tutar] )
Fiyatı 100 den Büyük Ürünler KÖTÜ :=
SUMX ('Satışlar'; IF ('Satışlar'[Fiyat] > 100; 'Satışlar'[Tutar] ) )
Fiyatı 100 den Büyük Ürünler CALCULATE :=
CALCULATE (
SUMX ( 'Satışlar'; 'Satışlar'[Tutar] ); 'Satışlar'[Fiyat] > 100
)
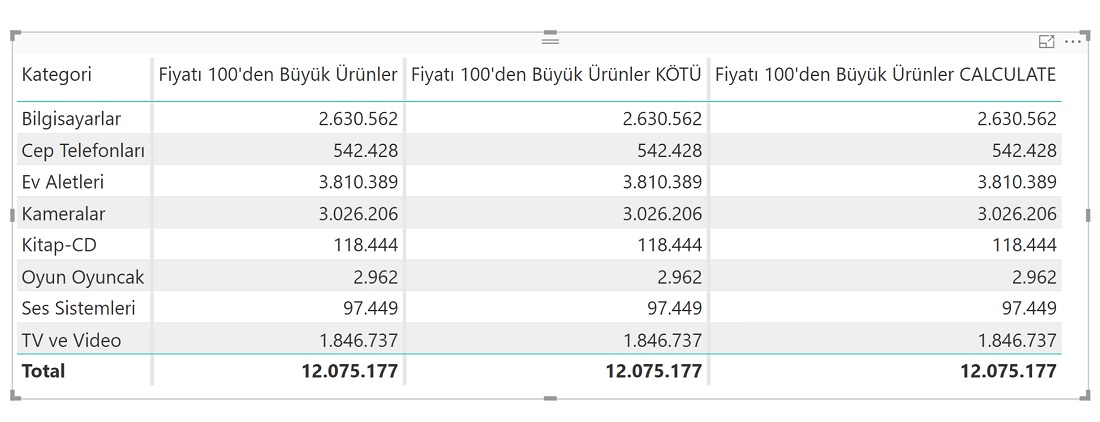
İlkinde; satış fiyatı 100’den büyük olan satırların olduğu tabloyu “iterate” edeceksin diyoruz, dolayısıyla iterate edeceğimiz tablonun satır sayısı doğrudan kısaldı.
İkincisinde; Satışlar tablosunda gördüğün tüm satırları iterate edeceksin, ve her bir satır için IF condition test edeceksin diyoruz.
Üçüncüsünde, ilk formüle benzer mantıkta fakat biraz daha farklı bir yöntemle tablon satış fiyatının 100’den büyük olduğu satırlardır diyoruz.
Her üç formül de aynı sonucu vermesine rağmen, hesaplama mantığı tamamen farklı.
‘Satışlar’ tablosu çok büyükse ve [Fiyat] sütunundaki “distinct” (unik) değer sayısı çok fazla ise ikinci yazdığımız formül hesaplamayı “Formula Engine”‘e taşırabilir.
En hızlı çalışacak formül CALCULATE versiyonlu olandır. [Fiyat] sütunu 100’den büyük olan satırları, sadece [Fiyat] sütununu kontrol ederek bir anda ayırır ve SUMX’e iletir.
FILTER bir iterator’dur. SUMX’e üzerinde çalışacağı tabloyu vermeden önce, ‘Satışlar’ tablosundaki her bir satırın [Fiyat] sütununu kontrol eder, işini bitirdiğinde fiyatı 100’den büyük olan satırların olduğu tabloyu SUMX’e iletir.
…
İterator’lar -aynen hesaplanmış sütunlar gibi- çalışmaya başladıklarında “row context” yaratır. Row Context, “şu an üzerinde çalıştığımız satır” demektir, yani “current row”‘dur.
Filter Context, kullanıcının koyduğu-seçtiği tüm filtrelerden, matristeki satır/sütun değerlerinden arta kalan verilerin olduğu data setidir.
Aynı anda hem “row context” hem de “filter context” mevcuttur. Satır bazlı işlem yapan bir iterator yoksa bile “row context” vardır, fakat “boştur”.
Eğer blogu düzenli takip edenlerdenseniz bu yazıyla birlikte aşağıdaki yazılara da tekrar bakmanızı tavsiye ederim. DAX öğrenebilmek için temel şart “context” kavramını ve tablolar arası ilişkilerin çalışma şeklini doğru anlamaktan geçiyor.
Veri Modeline Giriş, Hesaplanmış Sütun vs Metrik, DAX’a Giriş