Yazının başlığını ne koyarsam daha doğru olur diye biraz düşündüm açıkçası, bugüne kadar gelen sorular, içinde bulunduğum projeler, Power BI ile bir şeyler yapmaya henüz yeni başlamış ve SQL bilgisi yüksek profiller, kullanılan ERP sistemini avcunun içi gibi bilenler, kendi alanına hakim power-user iş kullanıcılarını düşününce bazı gözlemlerimi ve değerlendirmelerimi aktarmak isterim.
En sık karşılaştığım durum, her kullanıcının kendine ait Excel dosyaları üretmesi gibi pbix dosyası, yani Power BI dosyası üretmesi. Hepsi birbirinden ayrık, bağımsız -sonuç olarak aynı veriyi defalarca çeken- modelcikler içeren dosyalar! Gerekçeleri anlamak mümkün, Power BI Desktop’u hiçbir lisansa gerek kalmadan kurabiliyorsunuz, her türlü veri kaynağına bağlanabiliyorsunuz, nispeten kolay, hemen bir takım matrisler grafikler üretebiliyorsunuz.
Kapsamlar ayrı ayrı modellenebilir, örneğin satış-bütçe ayrı bir model olabilir, finansal raporlar ayrı tasarlanabilir. Ama her bir kapsamla ilgili sadece tek bir model oluşturmak-geliştirmek ve geri kalan herkesin bu modeli kullanmasını sağlamak lazım.
…
SQL bilgisi son derece yüksek, kullandığı ERP’ye de hakim -ama henüz Power BI konseptleriyle düşünmeyen- profilde gördüğüm en net durum şu: Her şeyi SQL tarafında sorgular yazarak halletmeye çalışmak, neredeyse her bir rapor sayfası için bir sorgu yazıp, bu sorgunun sonuçlarını Power BI’da görüntülemeye çalışmak.
Power BI, rapor tabanlı bir uygulama değildir. Model tabanlı bir uygulamadır. Her bir rapor sayfası için -SSRS’te olduğu gibi- ayrı ayrı ama esasında aynı tablolar üzerinden farklı hesaplamalar yapan sorgulara ihtiyacımız yok! Kurduğunuz modelde birbiriyle ilişkisi (relationship) kurulmamış bir sürü tablonuz varsa bilin ki büyük ihtimalle doğru yapmıyorsunuz.
Müşterinin finansallarına ayrı bir sorgu, siparişlerine faturalarına ait ayrı bir sorgu yazarak sadece o raporları kurtarırsınız ve yaptığımız veri modeli olmaz!
Aslında konseptler neredeyse birebir aynı, bu profil hem çok avantajlı hem de handikaplı. Bir SQL prosedürünü veya on tane tabloyu join’leyen group by yapıp toplamını ortalamasını alan bir sorguyu elbette yazabilir ve kullanabilirsiniz. Ama o sorguyla sınırlı kalırsınız!
Anlık stok hesaplayan bir sorgu da yazabilirsiniz SQL’de. Sonucunu da Power BI ‘da gösterebilirsiniz. Ama bu yazdığımız sorgu bize sadece anlık stoğu verir! Stokların aylara göre ortalama tutarını göremeyiz. Son 3 aydır, 6 aydır hareket görmemiş stokları bulamayız. Bulmak istersek ayrı ayrı sorgular yazmak gerekir… Oysa sadece ve sadece stok hareketlerini çeksek, yani sadece ham hareketleri çeksek, istediğimiz hemen her şeyi Power BI tarafında modelleyebilir ve hesaplayabiliriz.
SQL tarafında veriyi aggregate etmek görebileceğimiz ve hesaplayabileceğimiz detayları daha baştan kaybetmemize yol açar.
Eğitimlerde tekrarladığım bir cümleyi burada da tekrarlamama müsade edin: SQL bilmek kesinlikle kıymetli bir artı, ama Power BI ‘da veri modeli kurarken SQL kodu yazabildiğinizi unutun, konseptler aynı, SQL’de yapabildiğiniz her şeyin Power BI ve DAX tarafında bir karşılığı var. Üstelik daha kolay ve hızlı.
Herhangi bir modelde bize lazım olan -neredeyse- tek şey, ERP’deki tablolardan sadece lazım olan sütunları içeren, hiç bir hesaplama yapmayan basit SELECT cümlelerinden oluşan view’lar.
Eğer SQL bilgisi yüksek bir kullanıcı iseniz bu yazıya göz atmak isteyebilirsiniz. Power BI ‘ın model tabanlı bir uygulama olması üzerine konunun duayenlerinden birinin yazısının linkini buraya bırakıyorum.
İçinde satışın, bütçenin, stoğun, finansalların, maliyet ve karlılığın, üretimin, lojistiğin olduğu bir modeli tek tek SQL sorgularıyla çözemeyiz, ama doğru bir veri modeli kurarak oluşturabiliriz.
…
Bir çok programlama dili birbirine benzer. Doğrudur. Diğer dillerde tecrübeli kullanıcılar farklı DAX kodlarına bakarak dilin nasıl çalıştığını anlayıp buna göre kod yazmaya çalışıyor. Bu sadece kısmen ve başlangıçta işinizi görecek bir yöntem. DAX basit bir dil, syxtax’ı gayet temiz ama kolay bir dil değil. Gözümüzü korkutmasın, bir modelde bize lazım olan metriklerin büyük çoğunluğunu yazmak için dilin uzmanı olmamız gerekmiyor.
DAX’ın üzerinde koştuğu hepi topu 4-5 tane temel konsept var: Filter context, row context, context transition, expanded tables gibi. Bu konseptlerin ayrı ayrı ve birlikte nasıl çalıştığı üzerinde kafa yormadan, düşünmeden DAX’ı çok iyi öğrenmek mümkün değil. Kod örneklerinden yola çıkarak dili öğrenmeye çalışmak yerine temel konseptlerin nasıl çalıştığını anlamak gerekiyor.
Aşağıda iki tane kod var:
Satış Primi :=
SUMX ( 'Müşteriler' ;
'Müşteriler'[Prim Oranı] * [Satışlar]
)
Satış Primi :=
SUMX ( VALUES ( 'Müşteriler'[Prim Oranı] ) ;
'Müşteriler'[Prim Oranı] * [Satışlar]
)
Ne kadar yakınlar birbirlerine değil mi? Her iki formülün sonucu da aynı çıkacaktır üstelik.
Fakat arada ciddi bir çalışma farkı var mantık olarak, ilki Müşteriler tablosunda gördüğü her bir müşteri için, ilgili müşterinin prim oranıyla ilgili müşterinin satışlarını çarpacak, en sonunda her bir müşteri için bulduğu rakamları toplayacaktır. Gördüğü Müşteriler tablosunda 10 milyon satır varsa, 10 milyon kez iterasyon yapacaktır.
İkincisi ise, gördüğü Müşteriler tablosundaki Prim Oranı sütununda bulunan her bir tekil değer için, bu değere sahip tüm müşterilerin satışlarını bulacak, en sonunda her bir tekil prim oranı için bulduğu rakamları toplayacaktır. Müşterilerin prim oranları hepi topu 4-5 farklı değer içeriyorsa, ikinci kod sadece bu kadar iterasyon yapacaktır.
10 milyon nerede, 5 nerede!
Buradaki sorun -eğer adına sorun diyeceksek- şu : Formülün kendisi, her ne kadar synxtax’ından ne yaptığını iç güdüsel olarak anlıyorsak da, üzerinde çalıştığı konseptler üzerinde hiçbir ipucu vermiyor! SUMX bir iterator, gördüğü tablonun her bir satırı için çalışacak ve row context yaratıyor. [Satışlar] bir metrik ve bu metriği çağırıyoruz. Başına CALCULATE yazmasak bile DAX başında CALCULATE varmış gibi çalıştırır. Ve CALCULATE ile bir metriği çağırdığımızda, eğer bir row context altında çalışıyorsa context transition gerçekleşir!
Son derece basit, bir o kadar da güçlü bir syntax!
Basit formüllerde neyin ne olduğunu iç güdüsel olarak anlasak da, biraz daha kompleks ve efektif formüller yazabilmek veya doğru yorumlayabilmek için teoriyi öğrenmek şart. Bu da hemen olmuyor, pratik etmeyi ve üzerinde düşünmeyi gerektiriyor. Ama bir kez anlamaya başladığımızda gerisi geliyor.
…
Veri ambarı ve veri modeli aslında ilişkisel veri tabanlarıyla aynı. Her şey entity relationship diagramından ibaret. (Türkçe özürlü olduğumu söylemiş miydim daha önce?) Modelleyeceğimiz verinin ve sürecin yapısını tam anlamadan doğru modeli kurmak, ezbere formülleri yazmak zor! Ama süreci doğru anlayıp doğru veri modeli tasarladığımızda hayat çok kolaylaşıyor. Ralph Kimball‘ın modelleme kurallarını çok basitleştirmek gerekirse, bize her bir entity için (ki bu müşteri, ürün, depo kodu, çağrı tipi, hesap kodu vs. her şey olabilir) bir tane master tablo lazım. Geri kalan her şey transaction!
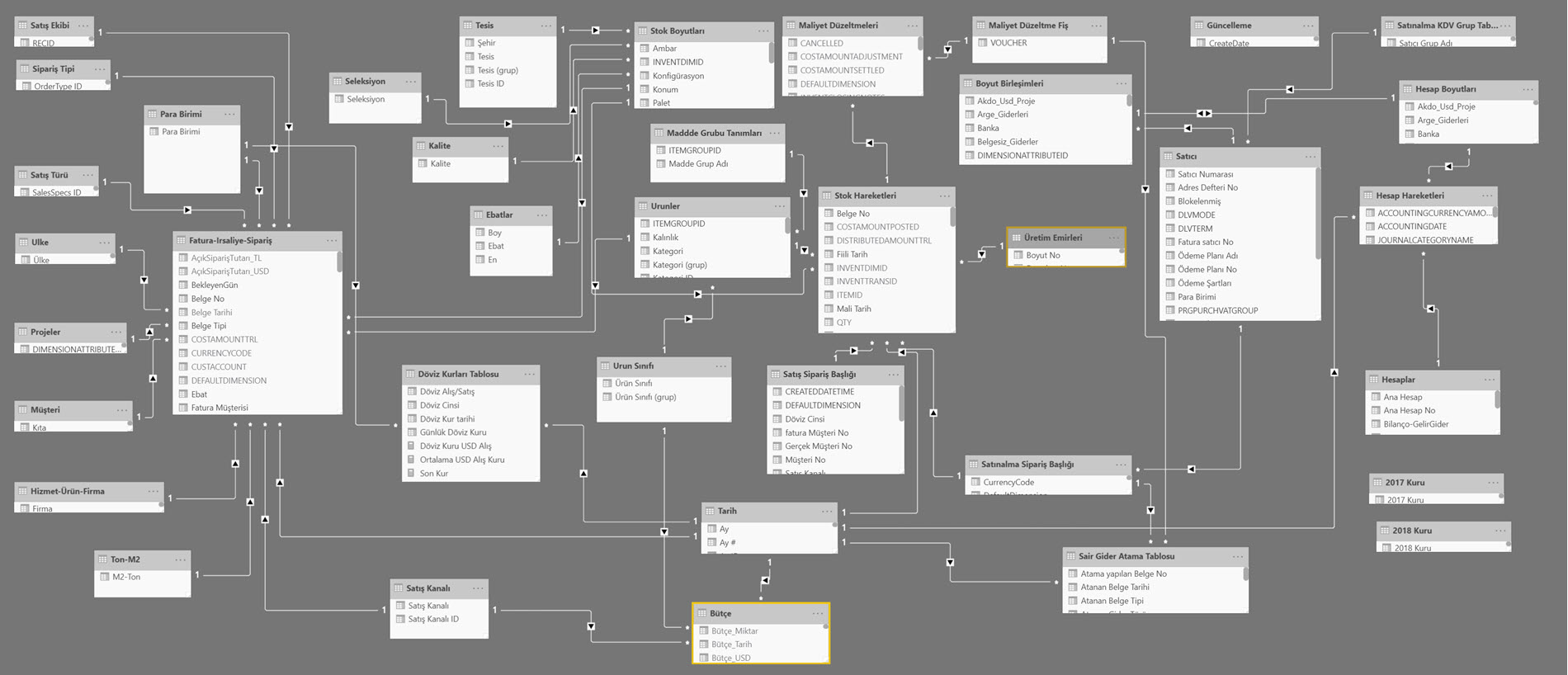
Aşağıdaki gibi bir veriyi bu haliyle doğrudan modellemeye kalkışamayız, ama buna benzer bir veriyi Power BI’a alıp iyi kötü bir şeyler yapabilir miyiz evet yaparız. Fakat doğru olmaz ve veri modeli konseptlerine uymamış oluruz! Bir noktadan sonra da tıkanırız.
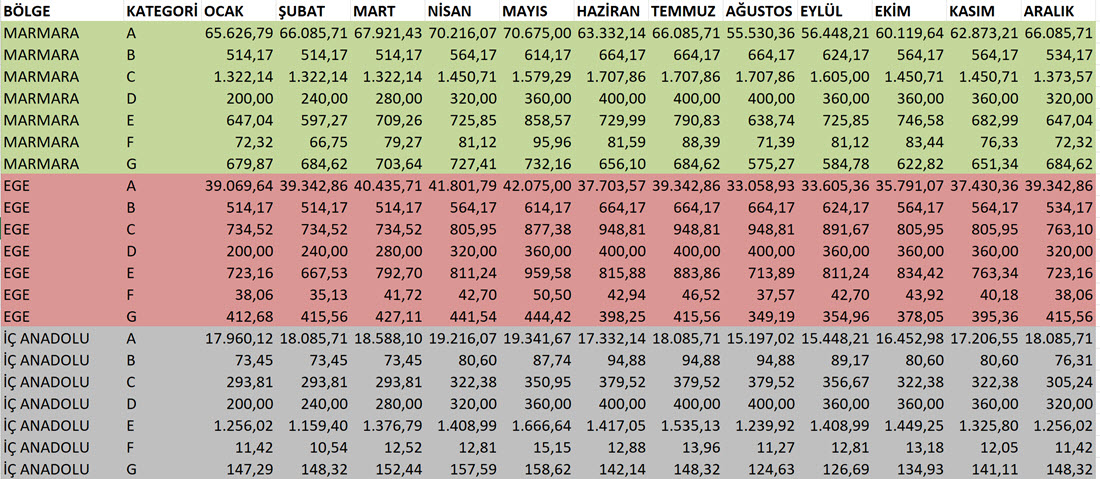
Resimdeki yapıdan devam etmek gerekirse, Bölge bir entity, dolayısıyla bize bir master tablosu lazım. Kategori de aynı şekilde. Sütunlarda gözüken tarih bilgisi de bir entity ve bunun da bir tablosunun olması lazım! Tek bir entity olduğu için de sütunlarda ayrı ayrı gözüken yapıyı satırlara almamız lazım!
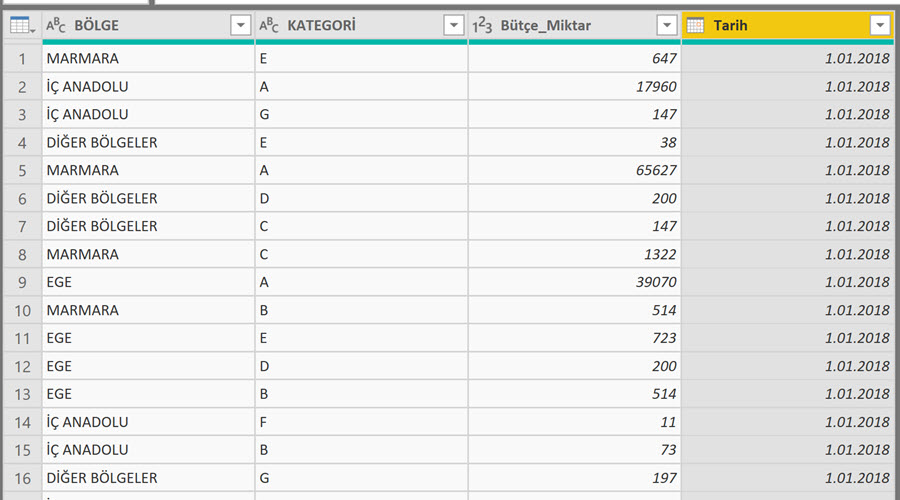
Gerisi ilişkileri kurmaktan ibaret!
…
Veri güncelleme hızının makul süresi modelin büyüklüğüne göre elbette değişir ama -devasa bir model değilse- yarım saati aşan sürelerin kabul edilebilir tarafı yok! Tablo veya view’lardan sadece lazım olan sütunları almak lazım. Dakika-saat seviyesinde detaya ihtiyacımız yoksa bu sütunların tipine “Date” demek lazım.
Görebildiğim kadarıyla veri yenilemeyi uzatan en önemli faktör Power Query tarafında gereksiz hesaplamalar yapmaktan kaynaklanıyor. Power Query bize SQL’de yapabileceğimiz her şeyi daha kolay yapma fırsatı sunuyor, bu doğru. Ama nihayetinde yaptığı şey SQL’e bir sorgu göndermek! Aynı sorguyu doğrudan SQL kodu olarak yazsanız ve F5’e bassanız ne kadar sürerse Power Query’nin veriyi oluşturup çekmesi de üç aşağı beş yukarı aynı oranda sürecektir.
Çok büyük satırlı tablolarla uğraşıyorsak basit Group By’lar haricinde fazla hesaplamaya girmemekte fayda var. Tabii bu arada query folding‘ten olabildiğince faydalanmak lazım.
…
Modelleme işinin elbette bir teknik boyutu var ve aslında çok zor değil. Teoriyi anlamaya yatırım yaptığınız sürece bir süre sonra her şey oturmaya başlayacaktır. Devamında önemli olan şey ise doğru rapor tasarımları oluşturmak. Bu aşamada süreci ve detayları iyi biliyor olmak, sürecin nasıl ölçülmesi gerektiği konusunda doğru metrikleri bilmek çok kıymetli. Konuyu bilmeden etkili raporlar üretmek zor.
Bu yüzden eğer teknik bir kullanıcı iseniz mutlaka süreci iyi bilen iş kullanıcılarıyla modellemeye girişmeden önce detaylı konuşun. Aksi taktirde rakamları yorumlamak da zor, raporları tasarlamak da.
…
Verinin görselleştirilmesiyle ilgili bazı temel kurallara uymakta fayda var. Neyin nasıl gösterileceği konusunda en önemli şey soruyu bilmek elbette ve bazı görseller hakikaten bazı soruları çok net cevaplıyor.
Örneğin bu sayfadaki bullet chart -veya benzerleri- herhangi bir metriği hem hedefe göre hem de başka bir değere göre karşılaştırmak için biçilmiş kaftan, ister gelir gider bütçesi için kullanın, ister üretim ve gerçekleşen karşılaştırması için. Hepsine uyar. Görselleştirmenin tek bir yöntemi yok, ama diğerlerine göre daha iyi ifade eden görseller her zaman için var.
İş zekası projeleri çok bacaklı bir süreç. Tek başına tekniği bilip süreçlerden bi’haber olmak -ya da tersi- başarılı bir proje için yeterli değil. Hepsini doğru bir şekilde harmanlamaya çalışmak gerekiyor.
Çok değerli bilgiler. Çok teşekkürler.
bir kez daha bu değerli bilgiler için çok teşekkürler. kararsız kaldığım bir konuda desteğinizi rica ediyorum.
benim çalışmamda powerbi’ya bağladığım dosyalar excel formatında. klasörler halindeki excel dosyalarına bağlanıp oluşan data üzerinde çalışıyorum. kullandığım dosyalar aylık verileri içeriyor ve toplamda bugünden geriye 5-6 yıllık veri var. bu eski verilere her an ihtiyaç duymuyorum ama ihtiyaç duyduğumda da kullanmak istiyorum.
bunun için query tarafında bir parametre oluşturup date sütunlarında buna göre filtre yaptım. bu parametreden sonraki tarihteki verileri sadece powerbi önyüzüne getiriyor. ancak powerbi’yı her çalıştırıp yenilediğimde tüm dosyaları baştan yenilediği için bekleme sürem artıyor. belli tarihten önceki verileri powerquery tarafında yenilememenin bir yolu var mı acaba?
Birden fazla sorguyu (bu durumda sizin Excel’ler) Power Query tarafında birleştiriyorsanız (append) ve query steplerinde bu dosyaları refere ediyorsanız her bir sorguya -refresh etmeyeceğim seni- deseniz bile bu dosyaları tek tek okuyor. Default davranışı bu. Dolayısıyla tarih filtresi verdiğinizde parametrik bile olsa sorgular öncesinde birleştiği için dosyalar her durumda okunuyor.
İki önerim olabilir, gene bir parametreye bağlayın sorgu kaynağını -diyelim- eğer 1 ise parametre X dizininden okusun dosyaları, 0 ise Y dizininden okuyun. X dizini tüm dosyalarınızı, Y dizini sadece yeni dosyaları içersin. Dizin okumayla ilgili bu yazıya da göz atabilirsiniz. https://powerbi.istanbul/tablolari-birlestirme-append-ve-dizin-okuma/
İkincisi ise dataflow ları kullanmak olabilir. Bu arkadaş yapmış böyle bir şey.
https://www.youtube.com/watch?v=u7SyqTpLIJc
Ya da tüm excel tablolarını bir sql tabloya eklerseniz mevcutta kullandığınız tarihi parametreye bağlama işi çalışacaktır.
Süreyi kısaltmak için bir önerim de şu: xls, xlsx formatı yerine csv formatını kullanın, daha hızlıdır.
çok teşekkürler. öneriniz kafamda oturdu, hemen deneyeceğim. csv formatında dosya boyutları daha büyüdüğü için olumsuz etki eder diye düşünmüştüm ama onu da kullanabilirim.